


ML a neurónové siete v praktických príkladoch / Scikit-learn: Ako trénovať nelineárne modely pomocou lineárnej regresie
Scikit-learn je populárna open source knižnica pre strojové učenie v Pythone, určená na jednoduché a efektívne riešenie úloh z oblasti dátovej analýzy, prediktívneho modelovania a strojového učenia. Knižnica obsahuje funkcie pre veľa užitočných algoritmov, ako je lineárna regresia, logistická regresia, SVM, náhodný les (random forest), KNN, zhlukovanie (clustering), PCA, redukcia dimenzií a mnohé ďalšie. Takisto obsahuje funkcie na prípravu údajov, škálovanie dát či rôzne transformácie. Scikit-learn umožňuje integráciu s knižnicami NumPy a SciPy a veľmi dobre spolupracuje s ostatnými vedeckými knižnicami Pythonu.

V jednoduchom, ale pomerne komplexnom príklade sa zameriame na funkciu PolynomialFeatures, ktorá slúži na generovanie nových príznakov (features) tak, že vytvára polynomiálne kombinácie pôvodných vstupných premenných. Používa sa predovšetkým na rozšírenie lineárnych modelov o nelineárne vzťahy medzi premennými.
Scikit-learn obsahuje aj niekoľko vzorových databáz, určených na cvičné príklady. V príklade budeme využívať dve databázy: fetch_california_housing a fetch_covtype. Pretože je dôležité vedieť, čo je cieľom analýzy alebo predikcie a v akej podobe sú údaje uložené, obidve databázy predstavíme podrobnejšie. Vybrali sme databázy, ktoré obsahujú reálne údaje, pretože v náhodne vygenerovaných databázach žiadne súvislosti nie sú, takže ani žiadne súvislosti neodhalíme.
Vzorová databáza fetch_california_housing obsahuje reálne údaje týkajúce sa bývania v Kalifornii, ktoré boli získané pri sčítaní ľudu z roku 1990. Táto databáza sa často používa pri nácviku a testovaní regresných modelov. Obsahuje 20 640 záznamov, má 8 vstupných atribútov, všetky sú numerické.
- MedInc – stredný príjem v oblasti (v desiatkach tisíc dolárov)
- HouseAge – priemerný vek domov v oblasti
- AveRooms – priemerný počet izieb na domácnosť
- AveBedrms – priemerný počet spální na domácnosť
- Population – počet obyvateľov v oblasti
- AveOccup – priemerný počet obyvateľov na domácnosť
- Latitude – geografická šírka oblasti
- Longitude – geografická dĺžka oblasti
Cieľová premenná MedHouseVal udáva strednú hodnotu ceny domu v obytnej štvrti v stovkách tisíc dolárov.
Vzorová databáza fetch_covtype obsahuje údaje z oblasti lesného hospodárstva zo Spojených štátov. Ide o „Covertype dataset“, ktorý pochádza z amerického ministerstva poľnohospodárstva a používa sa na klasifikáciu typu lesa či porastu podľa rôznych geografických a ekologických atribútov. Databáza má 581 012 záznamov a 54 vstupných atribútov. Hodí sa na úlohy typu klasifikácie, v tomto prípade na predikciu typu lesa v danej lokalite. Z už spomínaných 54 atribútov je 10 numerických: nadmorská výška, smer svahu, sklon, horizontálna vzdialenosť od vody, vertikálna vzdialenosť od vody, vzdialenosť od cesty, tiene o 9:00, 12:00 a 15:00 a vzdialenosť od požiarnych bodov. Ostatné atribúty sú binárne zakódované kategorické premenné. V nich je zakódovaných 40 druhov pôdy či druh oblasti. Výstupná premenná udáva typ porastu: smrek/jedľa, borovica obyčajná, borovica tmavšia, topoľ/vŕba, osika, Duglaska a Krummholz (typ zakrpatenej, zdeformovanej vegetácie tvarovanej prudkým mrazivým vetrom). Typ porastu je udávaný ako numerická hodnota 1 až 7.
Príklad môžete robiť na počítači s Windows, Linux aj Mac OS. Je potrebné mať nainštalovanú platformu Anaconda, knižnicu Scikit-Learn a vývojový nástroj Jupyter Lab. Celý príklad je ukázaný vo videu a na konci videa je podrobný postup inštalácie platformy Anaconda.
V konzolovej aplikácii Anaconda Prompt vytvoríme virtuálne prostredie, aby sme mali oddelené knižnice a nástroje pre tento príklad od ostatných úloh. Prostredie nazveme napríklad env_scikit. Na vytvorenie a aktivovanie virtuálneho prostredia a inštaláciu scikit-learn a Jupyter zadajte postupne príkazy:
conda create -n env_scikit python=3.12 conda activate env_scikit pip install scikit-learn pip install jupyter
Pre príklad vytvoríme samostatný adresár, napríklad s názvom Scikit1, a následne sa prepneme do tohto adresára.
mkdir Scikit1 cd Scikit1 Vývojový nástroj spustíme príkazom: Jupyter LabV prostredí Jupyter Lab najskôr importujeme cvičnú databázu fetch_california_housing a necháme vypísať jej atribúty a počet záznamov.
from sklearn.datasets import fetch_california_housing housing = fetch_california_housing() print(housing.data.shape, housing.target.shape) print(housing.feature_names) --------------------------- (20640, 8) ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude']Môžete si nechať vypísať vstupné atribúty prvého záznamu a aj výstupný atribút, teda cenu domu.
print(housing.data[0]) a takisto výstupný atribút, teda cenu domu print(housing.target[0]) ------------------------ 4.526Cena je v stovkách tisíc dolárov, teda ($100 000) x 4.526 = 452 600 USD. Do premennej x uložíme vstupné atribúty a do premennej y hodnotu výstupu:
x = housing.data y = housing.targetÚdaje rozdelíme na tréningovú a testovaciu množinu. Najčastejšie sa využíva rozdelenie v pomere 80 % údajov pre tréningovú a 20 % pre testovaciu množinu. Toto rozdelenie určuje parameter test_size=0.2. Údaje môžeme rozdeliť náhodne, zakaždým inak, prípadne náhodne s tým, že budú pri opakovanom spustení rozdelené rovnako. To určuje parameter random_state=42. Samozrejme, tu môže byť akákoľvek hodnota, ale z recesie sa často používa hodnota 42, čo je odpoveď na otázku o zmysle života, vesmíru a podobne z kultovej knihy Douglasa Adamsa Stopárov sprievodca galaxiou. Takže preto 42. Necháme vypísať počet záznamov v tréningovej aj testovacej množine:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split( x, y, test_size=0.2, random_state=42 ) print("trénovacia množina:", len(x_train)) print("testovacia množina:", len(x_test)) ----------------------------------------- trénovacia množina: 16512 testovacia množina: 4128Najskôr skúsime použiť model LinearRegresion. Na vyhodnotenie kvality predikcie budeme počítať parameter r2_score. R² je koeficient determinácie, ktorý udáva, aký podiel rozptylu cieľovej premennej dokáže model vysvetliť, ľudovo povedané, rozdiel medzi predpovedanými a skutočnými hodnotami. Napríklad hodnota 0.8486 znamená, že predikcia je úspešná v 84,86 % prípadov, odbornejšie povedané, model vysvetľuje 84,86 % variability v dátach.
from sklearn.linear_model import LinearRegression from sklearn.metrics import r2_score model = LinearRegression() model.fit(x_train, y_train) y_pred = model.predict(x_test) # predpoved r2 = r2_score(y_test, y_pred) # presnosť print("R2:", r2) ---------------- R2: 0.5757877060324521V tomto prípade hodnota 0.5757 udáva úspešnosť 57,6 %. Nie je to veľa, ale nejako treba začať. Teraz zapojíme do hry funkciu PolynomialFeatures, ktorá slúži na generovanie nových príznakov tak, že vytvára polynomiálne kombinácie pôvodných vstupných premenných. V tomto prípade je 8 pôvodných vstupných atribútov rozšírených na 45 atribútov.
from sklearn.preprocessing import PolynomialFeatures print("počet atribútov PRED", len(x_train[0])) poly = PolynomialFeatures() x_trainP = poly.fit_transform(x_train) x_testP = poly.fit_transform(x_test) print("počet atribútov PO:", len(x_train[0])) --------------------------------------------- počet atribútov PRED 8 počet atribútov PO: 45Vo finále vyskúšame viac modelov, každý s pôvodnými aj rozšírenými atribútmi, aby sme zistili, ktorý model je najvhodnejší. Budeme takisto merať čas spracovania.
from sklearn.ensemble import GradientBoostingRegressor from sklearn.ensemble import HistGradientBoostingRegressor from sklearn.ensemble import RandomForestRegressor import time # inicializacia modelov LR = LinearRegression() GBR = GradientBoostingRegressor() HGBR = HistGradientBoostingRegressor() RFR = RandomForestRegressor() # test modelov for model in [LR, GBR, HGBR, RFR]: start_time = time.time() model.fit(x_train, y_train) y_pred = model.predict(x_test) r2 = r2_score(y_test, y_pred) end_time1 = time.time() - start_time #s rozšírenými parametrami start_time = time.time() model.fit(x_trainP, y_train) y_predP = model.predict(x_testP) r2P = r2_score(y_test, y_predP) end_time2 = time.time() - start_time print("MODEL:", model) print("R2 = {}% T = {} s".format(round(r2 * 100, 2), round(end_time1, 4))) print("R2P = {}% T = {} s".format(round(r2P * 100, 2), round(end_time2, 4))) print("=====")
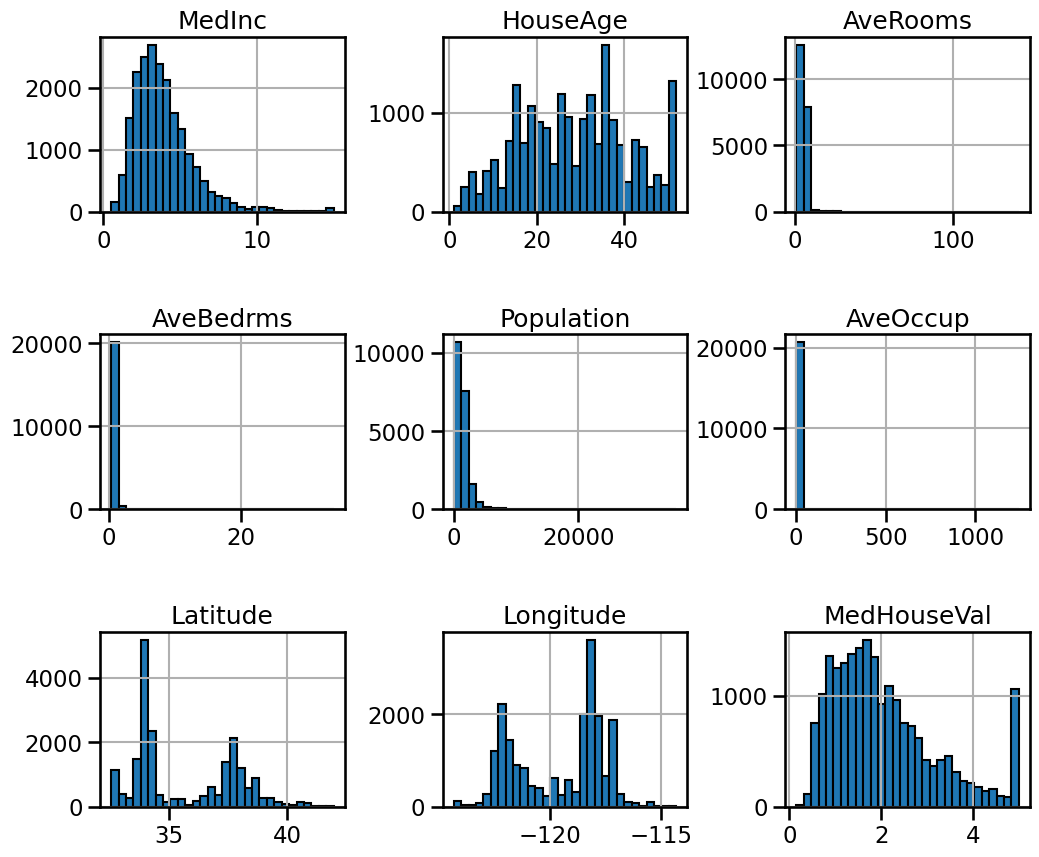
Grafy rozloženia údajov v cvičnej databáze fetch_california-Housing
Výsledky sú v tabuľke. R2 je úspešnosť modelu s pôvodnými ôsmimi vstupnými parametrami, R2 úspešnosť so 45 parametrami. Tabuľka obsahuje aj časy spracovania.
|
MODEL |
R2 |
Čas (s) |
R2P |
Čas (s) |
|
LinearRegression() |
57.58% |
0.004 s |
64.57% |
0.012 s |
|
GradientBoostingRegressor() |
77.56% |
3.676 s |
77.61% |
25.6878 s |
|
HistGradientBoostingRegressor() |
83.54% |
0.7874 s |
82.97% |
0.9743 s |
|
RandomForestRegressor() |
80.42% |
12.7012 s |
79.8% |
74.7379 s |
Jednoznačne najlepší a zároveň najrýchlejší je model HistGradientBoostingRegressor. Porovnaním časov spracovania s pôvodnými a rozšírenými atribútmi sme zistili, že pre niektoré modely je čas spracovania násobne dlhší.
Ten istý príklad urobíme s databázou fetch_covtype, ktorá je oveľa rozsiahlejšia. Má 581 012 záznamov a 54 vstupných atribútov. Tie sa pomocou funkcie PolynomialFeatures rozšíria na 1540 atribútov a to si už vyžaduje podstatne vyššiu výpočtovú náročnosť. Pre pomerne rýchly algoritmus LinearRegression je výsledok
MODEL: LinearRegression() R2 = 31.73% T = 1.0394 s R2P =48.04% T =53.584 sVýpočet s rozšírenými parametrami trvá viac než 50× dlhšie. Zatiaľ knižnica scikit-learn využíva len procesor, podstatne výkonnejšia grafická karta zostáva nevyužitá. Preto necháme vypísať len výsledky a časy s pôvodným počtom parametrov.
|
Model |
R2 (%) |
Čas(s) |
|
LinearRegression() |
31.73 |
1.0394 |
|
GradientBoostingRegressor() |
46.58 |
164.657 |
|
HistGradientBoostingRegressor() |
65.93 |
4.9708 |
|
RandomForestRegressor() |
92.64 |
506.3466 |
Najvyššiu úspešnosť má model RandomForestRegressor(), ale čas spracovania so 45 parametrami je 506 sekúnd. Netrúfame si odhadnúť, koľko by trvalo spracovanie s 1540 atribútmi. Preto v budúcom pokračovaní ukážeme, ako na scikit-learn využiť grafickú kartu. Tá to zvládne v rozumnom čase.
Zobrazit Galériu


