


Lokálne spúšťanie modelov AI v prostredí LM Studio
LM Studio je pokročilé prostredie na vývoj a nasadenie modelov AI, ktoré podporuje lokálne spúšťanie. Je navrhnuté tak, aby poskytovalo intuitívne používateľské rozhranie a robustné funkcie naprácu s modelmi AI. Umožňuje používateľom prispôsobiť si prostredie podľa vlastných potrieb a preferencií. Poskytuje nástroje na predspracovanie dát, tréning modelov a hodnotenie výkonu a takisto podporuje automatizáciu rutinných úloh. Výhodou je aj aktívna komunita používateľov, ktorá poskytuje podporu a zdieľa skúsenosti.

LM Studio je k dispozícii na najpoužívanejších operačných systémoch Windows, Linux aj Mac OS. Pre Windows je natívne podporovaná nielen platforma x64, ale aj ARM, takže program veľmi dobre beží na notebookoch s procesormi Snapdragon X Elite. Mac OS je podporovaný od verzie 24.0 pre počítače s čipmi Apple Silicon (M1/M2/M3/M4). Podporovaný je aj Ubuntu Linux od verzie 20.04, ale v systémových požiadavkách je uvedené, že verzie novšie než 22 zatiaľ ešte neboli dôkladne otestované. Pre Linux je podporovaná zatiaľ len platforma x64. Pre všetky platformy sa ako minimum odporúča aspoň 16 GB RAM.
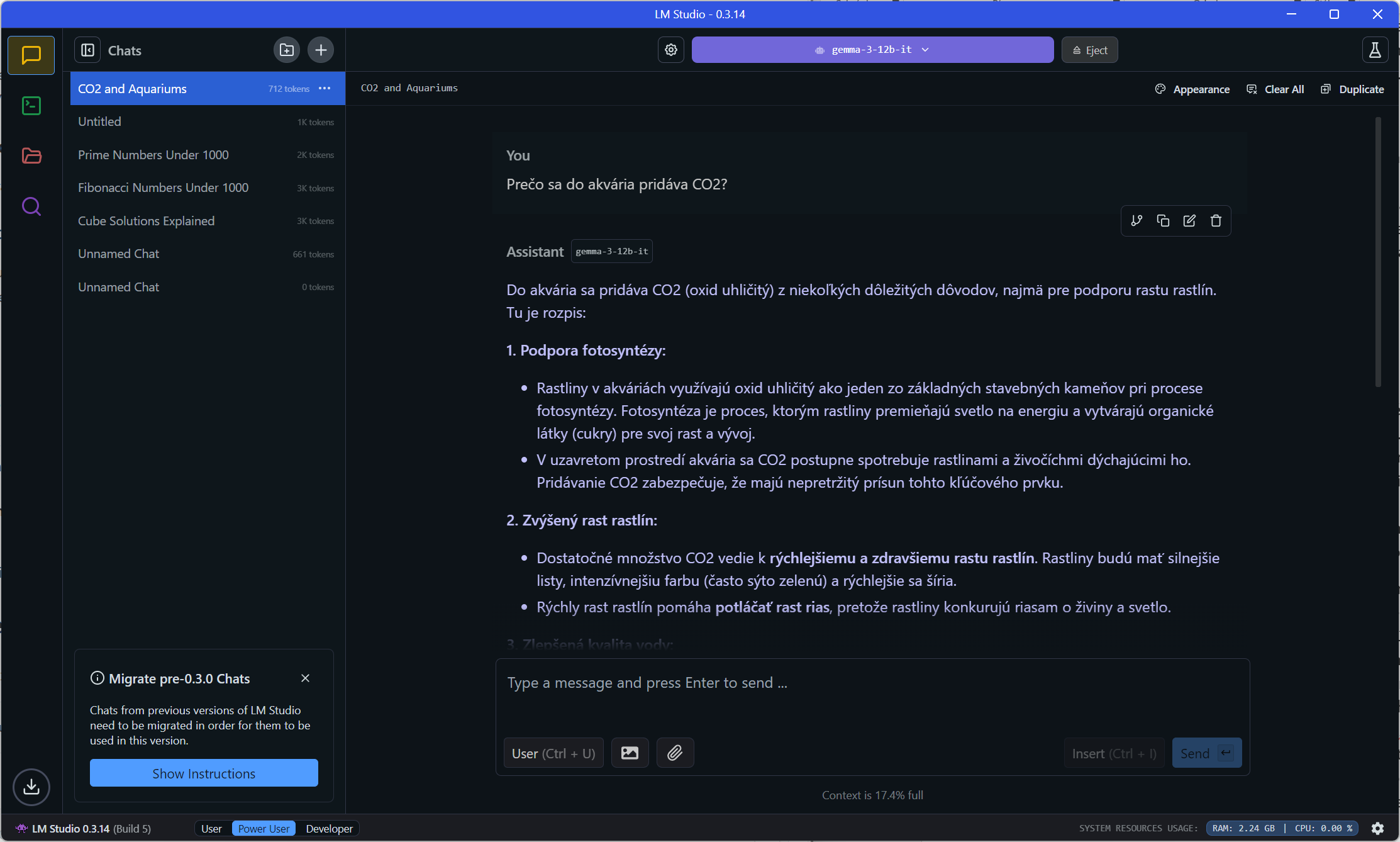
Chat s modelom Gemma-3-12b v slovenčine
Používanie je jednoduché, stačí načítať model a v rozhraní podobnom, ako používajú cloudové služby, môžete začať s modelom četovať. Vpravo dole možno prepínať komplexnosť používateľského rozhrania, pričom máte k dispozícii voľby User, Power User a Developer. Konverzácia sa uchováva v súboroch vo formáte JSON, vo Windows v priečinku
C:\Users\používateľ\.cache\lm-studio\conversations.
V systémoch Mac a Linux je to priečinok ~/.lmstudio/conversations/.
Priečinok s týmito súbormi zobrazíte, ak v kontextovom menu pre konverzácie v ľavom okne aktivujete voľbu Show in File Explorer. Pripomíname, že model nevyužíva informácie z četov na učenie.
Adresárová štruktúra modelov je:
~/.lmstudio/models/
└── publisher/
└── model/
└── model-file.gguf
Napríklad
\.lmstudio\models\lmstudio-community\gemma-3-12b-it-GGUF\gemma-3-12b-it-Q4_K_M.gguf
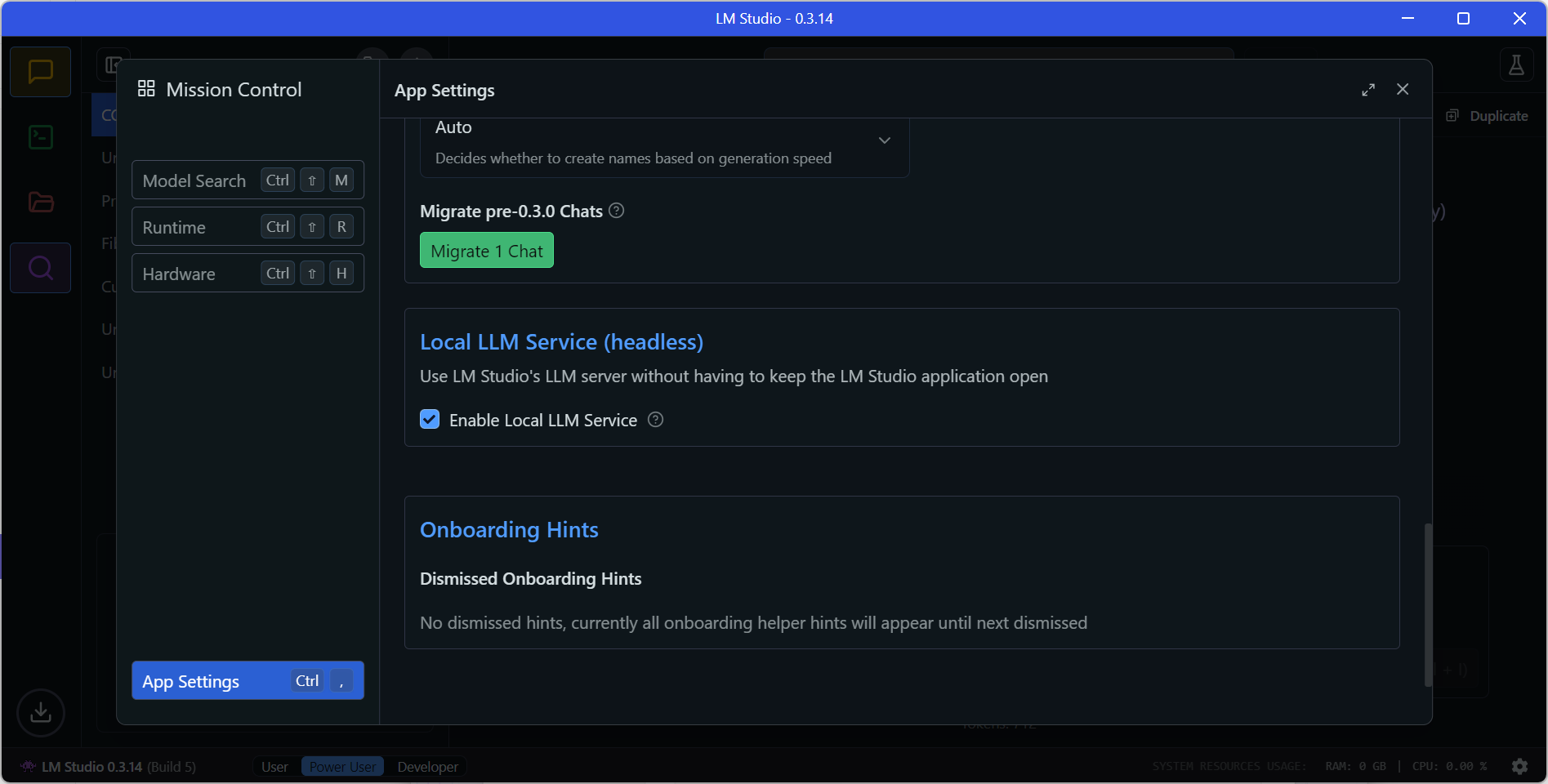
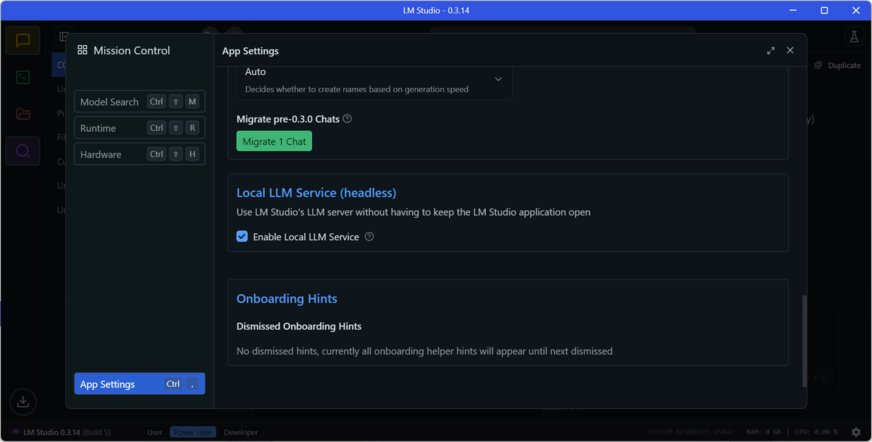
Povolenie fungovania LM Studia ako služby na pozadí
Súčasťou zadania môžu byť aj dokumenty. Súčasne môžete nahrať až 5 súborov s maximálnou kombinovanou veľkosťou 30 MB. Momentálne sú podporované formáty PDF, DOCX, TXT a CSV. Po uploade môžete četovať s vlastnými dokumentmi pomocou Retrieval Augmented Generation (RAG). LLM analyzuje vašu otázku a získané výňatky z vašich dokumentov a pokúsi sa vygenerovať odpoveď. Pri kladení otázok uveďte čo najviac podrobností. To pomôže systému získať z vašich dokumentov najrelevantnejšie informácie.
Ak je dokument krátky a hodí sa do kontextu modelu, LM Studio pridá obsah súboru do konverzácie v plnom rozsahu. Toto je obzvlášť užitočné pre modely, ktoré podporujú dlhšie veľkosti kontextu, ako napríklad Meta Llama 3.1 a Mistral Nemo. Ak je dokument veľmi dlhý, LM Studio využije RAG. RAG Sa pokúsi vyhľadať relevantné časti dlhého dokumentu alebo viacerých dokumentov a poskytne ich modelu. Táto technika niekedy funguje naozaj dobre, ale niekedy si vyžaduje určité ladenie a experimentovanie. Preto poskytnite vo svojom zadaní čo najviac kontextu. Uveďte výrazy, myšlienky a slová, ktoré očakávate v relevantnom zdrojovom materiáli. To často zvýši šancu, že systém poskytne LLM užitočný kontext.
LM Studio na spúšťanie modelov AI využíva softvérovú knižnicu llama.cpp s otvoreným zdrojovým kódom, ktorá interaguje s jazykovými modelmi AI. Knižnicu vytvoril Georgi Gerganov so zámerom prísnej správy pamäte a viacvláknového spracovania, aby sa zvýšil výkon na počítačoch bez GPU alebo iného špecializovaného hardvéru. Hoci bola knižnica pôvodne navrhnutá pre CPU, neskôr bola pridaná podpora aj GPU. Knižnica je priebežne zlepšovaná. V marci 2024 americká vývojárka Justine Tunney vytvorila nové optimalizované algoritmy násobenia matíc pre CPU x86 a ARM, čím zlepšila výkon rýchleho vyhodnocovania pre FP16 a 8-bitové kvantizované dátové typy.

Výber modelu na stiahnutie
Llama.cpp podporuje kvantizáciu modelu vopred na rozdiel od kvantizácie za behu a takisto podporuje takzvané špekulatívne dekódovanie. Spolu s projektom llama.cpp Georgi Gerganov v spolupráci s komunitou ďalších vývojárov definoval formát súborov GGUF. Formát súboru GGUF (GGML Universal File, pričom GG sú iniciály tvorcu), je binárny formát, ktorý ukladá tenzory aj metadáta do jedného súboru a je určený na rýchle ukladanie a načítavanie údajov modelu. Súbory GGUF sa zvyčajne vytvárajú konverziou modelov vyvinutých pomocou inej knižnice strojového učenia, ako je napríklad PyTorch. Formát sa zameriava na kvantizáciu, čo je proces znižovania presnosti váh modelu. Tento proces môže viesť k zníženiu využitia pamäte a zvýšeniu rýchlosti, ale na úkor nižšej presnosti modelu. Po natrénovaní modelu sa na parametre čiže váhové a bias koeficienty aplikuje kompresia, a to tak, že sa zmenší počet bitov potrebných na uloženie koeficientov z 32 alebo 16 bitov až na 3-4 bity. Modely sú spravidla k dispozícii v rôznych verziách líšiacich sa označením, napríklad Q3_K_S, Q_8 a podobne, pričom Q znamená Quantization čiže model s komprimovanými parametrami.
Už spomínané špekulatívne dekódovanie je technika, ktorá môže podstatne zvýšiť rýchlosť generovania rozsiahlych jazykových modelov bez zníženia kvality odpovede. Využíva spoluprácu dvoch modelov: väčšieho hlavného modelu a menšieho rýchlejšieho, takzvaného návrhového modelu. Počas generovania návrhový model rýchlo navrhuje potenciálne tokeny (podslová), ktoré hlavný model dokáže overiť rýchlejšie, ako by mu trvalo ich vygenerovanie od začiatku. Na zachovanie kvality hlavný model akceptuje iba tokeny, ktoré zodpovedajú tomu, čo by vygeneroval. Po poslednom akceptovanom návrhovom tokene hlavný model vždy vygeneruje jeden ďalší token. Aby sa model mohol použiť ako návrhový model, musí mať rovnaký „slovník“ ako hlavný model. Návrhový model má však menší počet parametrov. Napríklad
|
Hlavný model |
Návrhový model |
|---|---|
|
Llama 3.1 8B Instruct |
Llama 3.2 1B Instruct |
|
Qwen 2.5 14B Instruct |
Qwen 2.5 0.5B Instruct |
|
DeepSeek R1 Distill Qwen 32B |
DeepSeek R1 Distill Qwen 1.5B |
Špekulatívne dekódovanie môžete povoliť v režime Power User alebo Developer. Načítajte model a potom v sekcii Špekulatívne dekódovanie na bočnom paneli četu vyberte návrh modelu.
LM Studio môžete využívať v aplikáciách aj ako službu na pozadí bez grafického používateľského rozhrania.
Zobrazit Galériu

