ML v Pythone 8 – príklad rozpoznávanie obrazu
V predchádzajúcej časti sme ukázali konfiguráciu NVIDIA CUDA pre výpočty pomocou grafickej karty. V ôsmej časti sa budeme venovať rozpoznávaniu obrazu. Potrebujete mať nainštalovanú platformu Anaconda a knižnicu PyTorch. Príklady sú koncipované tak, aby fungovali aj na PC, ktoré nemajú grafickú kartu NVIDIA.
Postup vytvorenia príkladov je v krátkom videu
Neurónová sieť ResNet
Pri rozpoznávaní obrazu využijeme už natrénovanú neurónovú sieť ResNet (Residual Neural Network) o ktorej sa viac dozviete napríklad na Wikipédii. Táto neurónová sieť bola vytrénovaná na obrovskej databáze obrazov Imagenet https://www.image-net.org/ ktorá obsahuje 150 GB farebných obrázkov Dokáže klasifikovať 1000 rôznych kategórií, ako sú predmety, časti tela, zvieratá, vozidlá a podobne. Kategórie sú vymenované v textovom súbore https://github.com/pytorch/hub/blob/master/imagenet_classes.txt Tento súbor využijeme v našom kóde
Reziduálna konvolučná hlboká neurónová siet’ ResNet má okrem klasických prepojení medzi dvoma bezprostredne po sebe nasledujúcimi vrstvami aj takzvané reziduálne skokové spojenia, čiže prepojenia vrstiev, ktoré po sebe bezprostredne nenasledujú. Takáto architektúra urýchľuje trénovanie a eliminuje problém takzvaného preučenia. Klasické architektúry konvolučných neurónových sietí neboli schopné škálovať na veľký počet vrstiev, čo malo za následok obmedzený výkon. Vrstvy, ktoré nie sú relevantné ResNet jednoducho preskakuje.
Príklad rozpoznávania obrazu
Budeme pracovať v pracovnom priestore, ktorý sme vytvorili v predchádzajúcom dieli. Máme tam nainštalovanú knižnicu PyTorch. Ak máte v PC alebo notebooku grafickú kartu NVIDIA určite využite vyšší výpočtový výkon prostredníctvom GPU s využitím platformy NVIDA CUDA. Postup inštalácie je tiež v predchádzajúcom dieli.
V konzolovej aplikácii Anaconda PowerShell Prompt sa prepneme sa do príslušného pracovného priestoru v našom prípade do ll_ML
conda activate ll_ML
a nainštalujeme tam ešte aj knižnicu Pandas na prácu s údajmi ak ju ešte nemáte nainštalovanú
conda install pandas
Knižnica PIL (Python Imaging Library) https://pillow.readthedocs.io/en/stable/ je súčasťou platformy Anaconda.
Tento príklad môžete spustiť aj v prípade ak nemáte grafickú kartu NVIDIA. Vtedy použite riadky pre CPU, ktoré sú v komentári a do komentára dajte riadky kódu určené pre GPU. Do adresára, ktorý využíva PyTorch, v našom prípade je to adresár aktívneho používateľa skopírujte nejaký obrázok. Môže to byť obrázok vášho zvieratka, auta a podobne. Ja som použil obrázok nášho yorkšíra Tobbyho v súbore tobby1.jpg. Ak máte všetko správne nainštalované a nakonfigurované, mal by sa vám v prostredí Jupyter Notebook váš obrázok zobraziť pod blokom kódu.
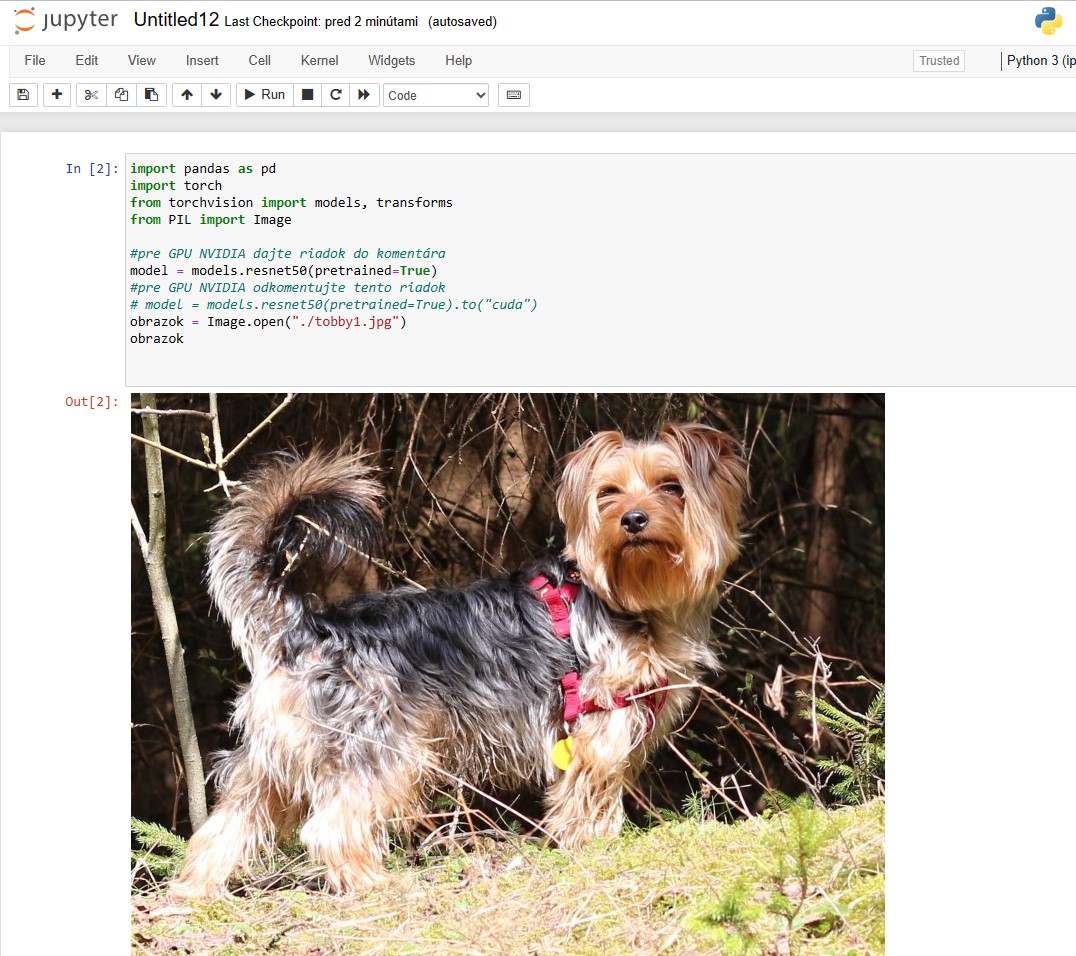
Na obrázok ktorý má v našom prípade veľkosť 754 x 567 pixelov a je v súbore, ktorý má 189 kB je potrebné aplikovať niekoľko transformácií. Najskôr ho zmenšíme povedzme na 256 pixelov. Prvá transformácie teda bude zmena veľkosti, v našom prípade sa kratšia strana zmenší na 256 pixelov
Príkazom print(obrazok_t.size) zistíte rozmery obrázku po zmenšení, v našom prípade má obrázok teraz rozmery 340 x 256 pixelov. Samozrejme rozpoznávanie nebude pracovať s obrázkom ako takým, ale s údajmi. Príkaz transforms.ToTensor() prekonvertuje obrázok do takzvaného tenzora, čiže viacrozmernej dátovej štruktúry. Neurónová sieť očakáva takzvaný normalizovaný vstup. To znamená, že je potrebné zmenšiť rozsah hodnôt bez ovplyvnenia ich pomerov. Parametre pre normalizáciu príkazom transforms.Normalize() sme prevzali z príkladu z dokumentácie k platforme PyTorch https://pytorch.org/vision/stable/transforms.html V dokumentácii na tejto stránke sa dozviete viac podrobností o transformáciách. V tomto príkaze urobíme dve transformácie súčasne. Mohli sme tu samozrejme urobiť naraz všetky transformácie, čiže aj transformáciu zmeny veľkosti, ale chceli sme pre názornosť zmenšený obrázok aj zobraziť, takže sme ju urobili samostatne
Objekt obrazok_t sa po týchto transformáciách už nezobrazí ako obrázok, ale ako tenzor, čiže viacrozmerná štruktúra. Výpis na obrázku je samozrejme skrátený
Tenzor v tomto pre každý pixel z matice 256 x 340 obsahuje tri hodnoty pre farebné zložky RGB. Necháme si zobraziť parametre tenzora
print(obrazok_t.shape)
torch.Size([3, 256, 340])
Ak každá hodnota typu float zaberá 8 bajtov, tak náš tenzor, v tomto prípade trojrozmerná matica s rozmermi 3 x 256 x 340 zaberá v pamäti 3 x 256 x 340 x 8 = 2 megabajty. Údaje pre neurónovú sieť sa načítavajú v dávkach. Veľkosť dávky (batch size) určuje koľko dát sa použije v jednom cykle. Čim je hodnota väčšia, tým je zmena váh spôsobená väčšou vzorkou, takže odhad bude presnejší. Na druhej strane pri väčšej dávke je na výpočty potrebné viac pamäti. Väčšinou sa pracuje s veľkosťou dávky 32.
Na to treba pamätať pri príprave údajov. Prvý rozmer tenzorov udáva s veľkosť dávky. V našom prípade pre tenzor [3, 256, 340] by to znamenalo, že máme 3 obrázky na dávku. V tomto našom trojrozmernom tenzore však 3 znamená počet farebných kanálov, čiže hodnôt RGB udávajúcich počet červenej, zelenej a modrej pre každý farebný pixel. Preto musíme rozšíriť tenzor o ďalší rozmer, ktorý bude udávať veľkosť dávky. Použijeme príkaz torch.unsqueeze(). Parameter 0 znamená že tenzor rozširujeme o prvý rozmer Podrobnosti a príklad nájdete v dokumentácii
Príkazom eval() nastavíme model do hodnotiaceho režimu. Niektoré špecifické vrstvy modelu sa sa správajú odlišne počas trénovania a vyhodnocovania, takže príkaz eval() tieto vrstvy pri hodnotení vypne. Okrem toho je pri vyhodnocovaní dobrou praxou vypnúť gradienty príkazom torch.no_grad(). Gradienty, ktorým sa budeme venovať neskôr potrebujeme len pri trénovaní modelu, pri rozpoznávaní obrazu ich môžeme vypnúť, aby nespotrebovávali cennú pamäť.
V premennej pravdepodobnosti je zoznam pravdepodobností všetkých kategórií obrázkov, ktoré nami použitý model pozná. Funkcia softmax je aj so vzorcom vysvetlená v dokumentácii PyTorch.
Nás zaujímajú triedy s najvyššou pravdepodobnosťou a výsledok potrebujeme v „ľudskej reči“ podľa už spomínaného zoznamu kategórií nášho modelu trénovaného podľa databázy obrazov Imagenet. Zo stránky si skopírujeme odkaz na surové údaje https://github.com/pytorch/hub/blob/master/imagenet_classes.txt a načítame to ako CSV súbor. Hodnoty síce nie sú oddelené čiarkou, avšak každý riadok obsahuje jeden údaj, takže v podstate je to CSV. Knižnici Pandas na prácu s údajmi sme sa venovali v druhej a načítaniu údajov z CSV v tretej časti nášho seriálu.
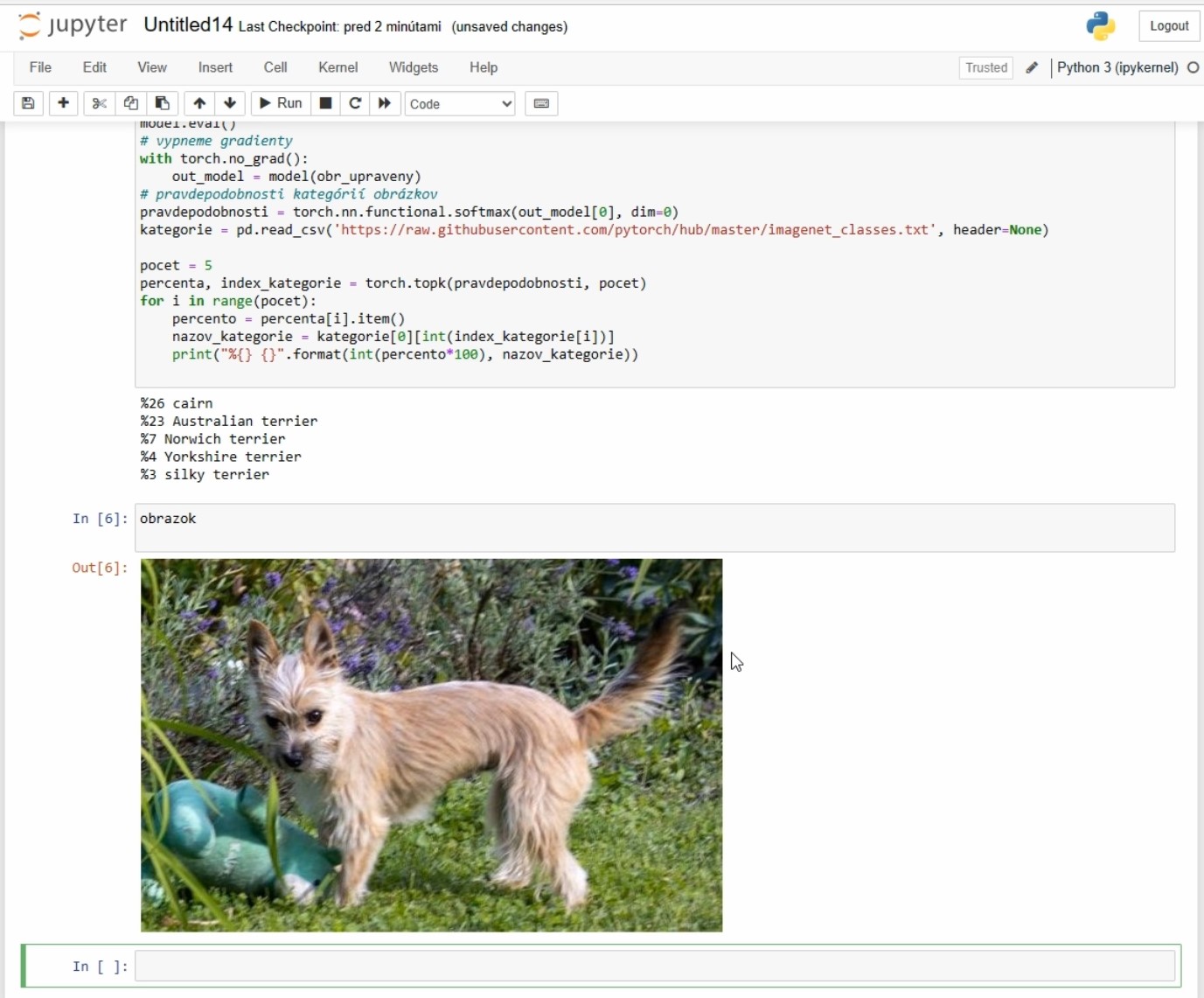
Chceme zobraziť päť najrelevantnejších odhadov. Na našom obrázku je pes charakteristického plemena, takže relevantných bude len niekoľko málo prvých odhadov. Funkcia topk() vracia dve hodnoty, pravdepodobnosť spolu s indexom kategórie. Pravdepodobnosť uložíme do pramennej percento. Je to desatinné číslo menšia ako 1, takže percentuálnu hodnotu dostaneme po vynásobení 100. Na základe indexu kategórie zistíme jej názov.
Na záver kompletná zdrojovka. Vo videu sú výsledky pre iný obrázok psíka kríženca
Rekapitulácia doterajších dielov
Zobrazit Galériu