


ML a neurónové siete v praktických príkladoch / 1-bitové jazykové modely AI
Vieme, že začínať vetu či dokonca nadpis číslom je proti pravidlám štylistiky, ale uchýlili sme sa k tomuto prehrešku, aby sme upriamili pozornosť na prívlastok jednobitové. Microsoft takýto model, konkrétne BitNet b1.58 2B4T, sprístupnil na portáli Hugging Face.
Jednobitové jazykové modely, nazývané aj bitnety, fungujú na princípe binárnych rozhodnutí, kde každý neurón v neurónovej sieti môže byť buď zapnutý, alebo vypnutý. Hoci to môže vyzerať ako obmedzenie, tento prístup umožňuje rýchle a efektívne spracovanie informácií, čo je ideálne pre aplikácie vyžadujúce rýchlu reakciu.
V označení modelu BitNet b1.58 2B4T vás pravdepodobne zarazí, že v ňom za b nie je jednotka ako jednobitový, ale b1.58. Bitnety používajú jednobitové váhy s tromi možnými hodnotami: -1, 0 a +1 čiže technicky ide o „1,58-bitový model“ pre podporu troch hodnôt. Takéto modely sa nazývajú aj modely s ternárnou kvantizáciou počas dopredného prechodu. Aj tak si určite položíte otázku, prečo práve 1.58, a nie okrúhle 1.5 alebo 2. Súvisí to s experimentálnym nastavením a optimalizáciou modelovej architektúry tak, aby dosahovala čo najlepší výkon alebo aby využívala konkrétnu konfiguráciu, teda počet a šírku vrstiev, ktorá práve vedie k 1,58B parametrom. Nízkobitové reprezentácie váh znižujú nároky na výpočtový výkon a takéto modely sú menšie, čiže šetria veľa pamäte v porovnaní s bežnými modelmi AI s 32-bitovými alebo 16-bitovými parametrami, či už v plnom rozsahu, alebo komprimovanými. Takýto model je, samozrejme, v porovnaní s väčšími modelmi menej presný. BitNet b1.58 2B4T to však vynahrádza rozsiahlymi tréningovými dátami. Ak budeme pokračovať v dekódovaní názvu modelu, 2B znamená, že model má dve miliardy parametrov (B – billions) a 4T znamená, že model bol trénovaný na štyroch triliónoch tokenov. Trilión znamená tisíc miliárd čiže 1012. Na lepšiu predstavu, takýto objem textu obsahuje 30 miliónov kníh.
Ak to zhrnieme, jednobitový open source model BitNet b1.58 2B4T s dvoma miliardami parametrov natrénovaný na štyroch biliónoch tokenov je natoľko kompaktný, že dokáže efektívne fungovať aj na CPU. Klasické modely LLM bežia podstatne rýchlejšie na grafických procesoroch. Model je dostupný na Hugging Face, čo umožňuje komukoľvek s ním experimentovať. Aby sme boli presní, na portáli Hugging Face sú dostupné tri varianty tohto modelu:
- bitnet-b1.58-2B-4T s 1,58-bitovými váhovými parametrami, určený na priame nasadenie. Model má 1,18 GB.
- bitnet-b1.58-2B-4T-bf16 obsahuje váhy vo formáte BF16. Tento model je určený na trénovanie a dolaďovanie. Zaberá 4,83 GB.
- bitnet-b1.58-2B-4T-gguf má váhové parametre vo formáte GGUF, takže sú kompatibilné s knižnicou bitnet.cpp. Zaberá 1,84 GB.
Modely AI sú často kritizované za to, že na trénovanie a prevádzku spotrebúvajú príliš veľa energie. Spotreba pri trénovaní jednobitových modelov je pravdepodobne podobná ako pri trénovaní klasických modelov, ale je to jednorazová záležitosť. Takýto model sa však následne lokálne spúšťa na veľkom množstve počítačov a tam nižšie výkonové nároky, a teda aj nižšia spotreba zaváži. Takéto modely umožnia prístup k lokálnej AI aj bez toho, aby potrebovali výkonné a drahé grafické karty, prípadne najnovšie procesory s NPU. Zatiaľ bitnet.cpp beží na CPU, neskôr bude k dispozícii aj podpora GPU a NPU.

Inštalácia knižnice PyTorch
Má to však aj malý háčik. Tím z Microsoft Research výslovne uviedol, že tento model pri použití so štandardnou knižnicou transformátorov nebude mať adekvátny výkon. Klasické knižnice totiž neobsahujú špecializované, vysoko optimalizované výpočtové algoritmy, potrebné na využitie výhod architektúry BitNet. Spustenie modelu prostredníctvom klasických transformerov pravdepodobne povedie k rýchlostiam a spotrebe energie porovnateľným alebo potenciálne horším ako pri štandardných modeloch. Bitnetové modely LLM preto musia na efektívne fungovanie použiť knižnicu bitnet.cpp, ktorá je k dispozícii na GitHube.
Na portáli Hugging Face v záložke Model card nájdete postup inštalácie komponentov potrebných na spustenie modelu BitNet b1.58 2B4T a testovací kód v Pythone. V záložke Files v súbore model.safetensors je samotný model. Veľkosť súboru je 1,18 GB.
Ukážeme spustenie jednobitového modelu v operačnom systéme Ubuntu Linux. Model sa dá spustiť aj na počítači s Windows, no musíte mať nainštalovaný WSL (Windows Subsystem for Linux) a treba vyriešiť dva drobné problémy.
Začneme Ubuntu Linuxom. Najskôr aktualizujeme operačný systém a všetky komponenty:
sudo apt update sudo apt upgradeNa použitie s GPU NVIDIA s existujúcimi knižnicami budeme potrebovať NVIDIA Cuda compiler (nvcc). O tom, či je nainštalovaný, sa presvedčíme príkazom:
nvcc --versionAk tento kompilátor nainštalovaný nemáte, postup inštalácie je na docs.nvidia.com/cuda/cuda-installation-guide-linux.
Knižnica PyTorch, ktorú budeme využívať, nie je zatiaľ dostatočne otestovaná s najnovšími verziami Pythonu. Preto ak máte novšiu verziu ako 3.12, bude potrebné vytvoriť virtuálne prostredie a do neho nainštalovať požadovanú verziu, konkrétne Python 3.12. Najskôr teda zistíme, akú verziu Pythonu máme nainštalovanú, príkazom:
Python3 --versionPožadovanú verziu Pythonu nainštalujeme príkazom:
sudo apt install python3.12-venvVytvoríme nový adresár, napríklad BitNetTest a prepneme sa do tohto adresára
mkdir BitNetTestcd BitNetTestvytvoríme virtuálne prostredie, napríklad z názvom envBitNet. Postup vytvorenia virtuálneho prostredia nájdete aj na našom kanáli YouTube vo videu Virtuálne prostredie pre Python projekty.
Python3 -m venv envBitNetVirtuálne prostredie aktivujeme príkazom:
source envBitNet/bin/activateTo, že sa nachádzate vo virtuálnom prostredí, je indikované na začiatku promptu, kde je názov virtuálneho prostredia v zátvorkách. V mojom prípade (envBitNet).
Na spustenie modelu potrebujete knižnicu PyTorch. Ak ju nemáte nainštalovanú, inštalačný skript nájdete na stránke pytorch.org. Pre Linux a CUDA 12.6 je inštalačný príkaz:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126Po nainštalovaní PyTorchu je potrebné nainštalovať knižnicu transformers, ale neinštalujte štandardnú knižnicu transformers. Na karte modelu na portáli Hugging Face nájdete príkaz na nainštalovanie verzie knižnice transformers určenej na tento účel.
pip install git+https://github.com/shumingma/transformers.gitInštalácia trvá jednu až dve minúty. Posledným prípravným krokom je inštalácia knižnice accelerate:
pip install accelerateNa karte modelu je aj vzorový kód, ktorý môžete skopírovať do vhodného vývojového prostredia, napríklad Visual Studio Code. V kóde stačia drobné upravy, ktoré sú vyznačené hrubým fontom. Do definície modelu pridajte parameter device_map = 'auto', aby sa model spustil na GPU, ak je k dispozícii, a upravíte prompt, napríklad: „Why sky is blue?“ Úpravy sú v zdrojovke vyznačené hrubým fontom.
import torch from transformers import AutoModelForCausalLM, AutoTokenizer model_id = "microsoft/bitnet-b1.58-2B-4T" # Load tokenizer and model tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained( model_id, torch_dtype=torch.bfloat16, device_map = 'auto' ) # Apply the chat template messages = [ {"role": "system", "content": "You are a helpful AI assistant."}, {"role": "user", "content": " Why sky is blue?"}, ] prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True) chat_input = tokenizer(prompt, return_tensors="pt").to(model.device) # Generate response chat_outputs = model.generate(**chat_input, max_new_tokens=50) response = tokenizer.decode(chat_outputs[0][chat_input['input_ids'].shape[-1]:], skip_special_tokens=True) # Decode only the response part print("\nAssistant Response:", response)
Teraz môžete model spustiť. Pri prvom spustení sa nahrá z portálu Hugging Face, takže reakcia na výzvu, ktorá je integrovaná priamo v kóde, potrvá trochu dlhšie.
Model možno spustiť aj na počítači s Windows, no potrebujete mať nainštalovaný WSL (Windows Subsystem for Linux). Postup inštalácie nájdete vo videu Inštalácia WSL na našom kanáli YouTube. Pracovať budeme v konzolovej aplikácii Príkazový riadok (CMD). Vytvoríme nový adresár, napríklad BitNetTest, a prepneme sa do tohto adresára.
mkdir BitNetTest cd BitNetTest python -m venv envBitNetVo Windows potrebujete nainštalovať aj knižnicu huggingface_hub. Jej opis nájdete na github.com/huggingface/huggingface_hub.
pip install -U "huggingface_hub[cli]"Inštalácia trvá niekoľko desiatok sekúnd. Následne použijeme príkaz login:
huggingface-cli loginKonzolová aplikácia vám oznámi, že na prihlásenie budete potrebovať token, ktorý si vygenerujete na adrese https://huggingface.co/settings/tokens. Po prihlásení sa na portál HuggingFace vygenerujte nový token typu Fine-grained, pričom v sekcii Repositories označte všetky tri voľby. Token zadajte v konzolovej aplikácii do prihlásenia na huggingface_hub. Po skopírovaní sa token v konzolovej aplikácii nezobrazí. Na prompt Add token as git credential? zadajte „n“. Konzolová aplikácia vám potvrdí úspešné prihlásenie. Potom nainštalujete PyTorch, pričom skopírujete a zadáte inštalačný príkaz pre Windows.
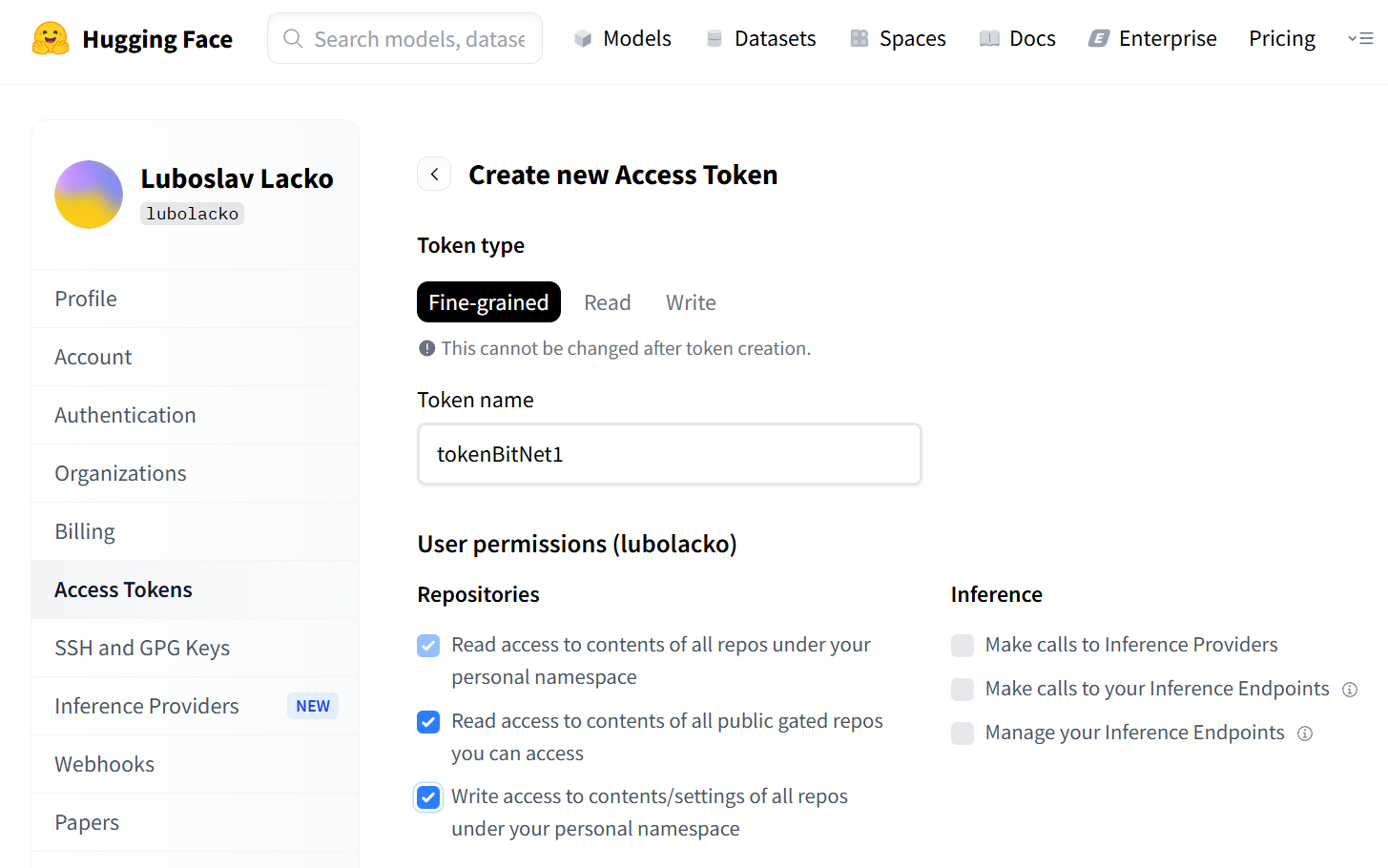
Vygenerovanie tokenu na portáli Hugging Face
Podobne ako v Linuxe pokračujete inštaláciou knižníc transformers a accelerate.
pip install git+https://github.com/shumingma/transformers.git pip install accelerateVzorový kód zo stránky modelu však po spustení vyhlási chybu: Canot find a working triton installation. V opise chyby je aj návod na vyriešenie. Do kódu za import torch treba pridať riadky:
import torch._dynamo torch._ dynamo.config.supress_errors = TrueAj teraz sa po spustení zobrazia nejaké upozornenia, ale za nimi sa zobrazí aj odpoveď na výzvu.
Zobrazit Galériu

