ML v Pythone 12 – neurónová sieť predpovedá výskyt cukrovky u indiánskeho kmeňa
V predchádzajúcej časti sme ukázali vytvorenie neurónovej siete natrénovanej na texte knihy generujúcej krátke poviedky. Príklad bol názorný a zrozumiteľný ohľadne toho ako sa neurónová sieť trénuje a čo robí, avšak vysvetliť začiatočníkovi ako funguje by bolo náročné. Príklad z generovaním textu bol tiež perfektný na demonštrovanie, že GPU si s úlohami tohto typu poradí oveľa rýchlejšie než CPU. Tento príklad bude jednoduchší, prehľadnejší a zrozumiteľný aj pre začiatočníkov.
Seriál je koncipovaný tak, že v každom dieli je kompletný príklad a postup je ukázaný vo videu
Ukážeme vytvorenie jednoduchej neurónovej siete, jej natrénovanie na vzorke údajov a následne bude táto neurónová sieť použitá na predpovedanie. Neurónovú sieť budeme trénovať na pomerne malej vzorke údajov, takže výpočty v pohode zvládne aj procesor, nepotrebujete GPU. Budeme používať knižnicu PyTorch. Príklad môžete vyskúšať v online prostredí Google Colaboratory, alebo v lokálne nainštalovanom prostredí Jupyter Notebook, ktorý je súčasťou platformy Anaconda.
Údaje na trénovanie NS
Aby bol príklad čo najnázornejší, potrebujeme vzorku údajov, ktorá bude zrozumiteľná. Na prednáškach o neurónových sieťach sa často používa vzorka údajov Pima Indians Diabetes Database. Najskôr vysvetlíme o aké údaje sa jedná. Indiáni z kmeňa Pima, žijúci v Arizone majú podstatne vyššiu náchylnosť na cukrovku druhého typu, než zvyšok populácie. Preto sa realizovalo veľa vedeckých prác s cieľom objasniť možnú patogenézu a faktory vedúce k vzniku tohto ochorenia, predovšetkým zistiť, či príčinou vysokého počtu ochorení na cukrovku je zmena stravovacích návykov. V rámci týchto prác bol realizovaný aj prieskum, pri ktorom sa zaznamenali zdravotné údaje testovaných osôb a sledovalo sa, či sa u nich do dvoch rokov objavila cukrovka.
Dataset s ktorým budeme pracovať obsahuje údaje o 768 ženách z kmeňa Pime, pričom po dvoch rokoch 258 z nich bolo pozitívne a 500 negatívne testovaných na cukrovku
Pre nás je dôležité, že všetky vstupné premenné, ktoré popisujú každého pacienta sú numerické, takže sa dajú priamo použiť pre neurónové siete ktoré, očakávajú číselné vstupné a výstupné hodnoty.
Údaje sú vo formáte CSV, čiže hodnoty oddelené čiarkou a ak budete príklad robiť na lokálnom počítači v prostredí Jupyter Notebook je potrebné uložiť ho niekam na disk. Ak budete príklad robiť v online prostredí Google Colaboratory, súbor s údajmi uploadujte na Disk Google. V našom prípade je súbor diabetes.csv v zložke ML Neuronova siet
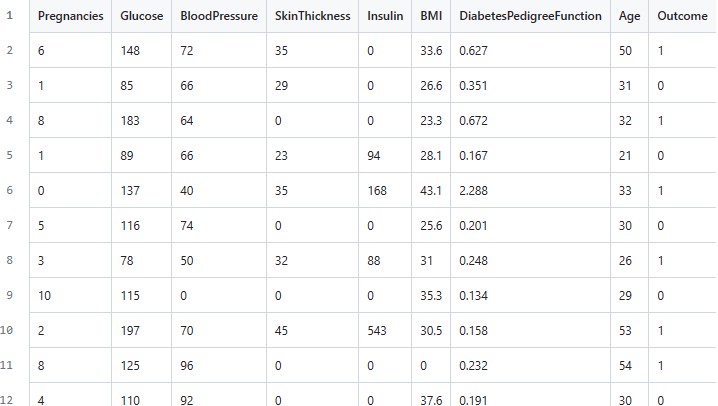
Súbor má 8 vstupných atribútov:
- Pregnancies - počet otehotnení
- Glucose - koncentrácia glukózy v plazme po 2 hodinách od vypitia roztoku glukózy
- BloodPressure - diastolický krvný tlak (mm Hg)
- SkinThickness - grúbka kožného záhybu tricepsu (mm)
- Insulin - dvojhodinový sérový inzulín (μIU/ml)
- BMI - index telesnej hmotnosti (hmotnosť v kg/(výška vm)2)
- DiabetesPedigreeFunction - funkcia vyjadrujúca pravdepodobnosť, že pacienti dostanú chorobu extrapoláciou z histórie ich predkov
- Age - vek
Výstupnou hodnotou je atribút Outcome, ktorý udáva, či sledovaný človek do piatich rokov cukrovku dostal (Outcome=1), alebo nedostal (Outcome=0).
Údaje potrebujeme rozdeliť na dve podmnožiny, trénovaciu a testovaciu. V trénovacej množine potrebujeme vstupné aj výstupné atribúty. V testovacej množine výstupný atribút odstránime.
- X – vstupné atribúty
- Y – výstupný atribút
Necháme vypísať vstupné atribúty (výpis je skrátený)
výpis výstupného atribútu (výpis je skrátený)
Údaje môžeme rozdeliť na množiny trénovacích a testovacích údajov. Mohli by sme to urobiť manuálne, a rozdeliť ich napríklad na polovicu.
Príkaz df.shape prezradí, že DataFrame obsahuje 768 záznamov, pričom každý z nich má 9 atribútov.
Nakoľko v tomto prípade máme relatívne málo záznamov budeme sa snažiť vyčleniť čo najviac záznamov pre trénovaciu množinu. Na rozdelenie údajov použijeme funkciu train_test_split z knižnice scikit-learn.
Tieto údaje zatiaľ uložené v poliach je potrebné najskôr prekonvertovať na tenzory. Jedným z dôvodov je, že PyTorch pracuje v 32-bitovej pohyblivej rádovej čiarke, zatiaľ čo NumPy používa 64-bitovú pohyblivú rádovú čiarku a nesúlad dátových typov prináša mnohé problémy.
Výpis potvrdí, že X_train, X_test, y_train a y_test už nie sú polia, ale tenzory
Trénovacie aj testovacie údaje máme pripravené a prekonvertované na tenzory, takže môžeme definovať model.
Definovanie modelu
Model definujeme ako postupnosť vrstiev. Prvá vrstva musí mať správny počet vstupných funkcií. V našom prípade máme dátovú množinu, ktorá má 8 vstupných atribútov. Takže zadáme vstupný rozmer 8 pre osem vstupných premenných, ktoré budú tvoriť jeden vektor. Ďalej sa treba rozhodnúť, koľko skrytých vrstiev bude mať neurónová sieť. Môžete vychádzať zo skúseností, alebo využiť metódu pokus-omyl. Štruktúra neurónovej siete je vždy aj o kompromisoch. Potrebujete sieť dostatočne veľkú na zachytenie štruktúry problému, ale na druhej strane nie príliš veľkú, aby nebola príliš pomalá. V tomto príklade použijeme úplne prepojenú sieťovú štruktúru s dvomi skrytými vrstvami.
Model vytvoríme ako triedu zdedenú z modulu nn.Module. Trieda musí mať všetky vrstvy definované v konštruktore __init__, pretože pri jej vytváraní musíte pripraviť všetky jej komponenty, avšak zatiaľ nie je k dispozícii vstup. Taktiež musíte zavolať konštruktor nadradenej triedy super().__init__(). V triede musíte tiež definovať funkciu forward() v triede, aby ste povedali, ak je poskytnutý vstupný tenzor x, ako na oplátku vytvoríte výstupný tenzor.
Plne prepojené vrstvy v našom prípade sú to husté vrstvy sú definované pomocou metódy nn.Linear v PyTorch. Je to operácia podobná násobeniu matíc. Modul nn.Linear má dva parametre: in_features a out_features, ktoré predstavujú počet vstupných a výstupných funkcií. Keď je objekt nn.Linear vytvorený, náhodne inicializuje maticu váh a vektor skreslenia. Veľkosť matice váh je out_features krát in_features a veľkosť vektora odchýlky je out_features.
Vstup druhej transformácie (20) je výstupom prvej a to isté platí aj pre tretiu transformáciu so vstupom 20.
- Model očakáva záznamy (riadky údajov) s 8 premennými
- Prvá skrytá vrstva má 20 neurónov
- Druhá skrytá vrstva má 20 neurónov
- Výstupná vrstva s dvomi hodnotami
Dopredný prechod je realizovaný ako metóda forward() sa volá, vtedy, keď neurónovú sieť použijeme predpovedanie. Vtedy informácie prúdia „dopredu“ zo vstupu cez skryté vrstvy na výstup. Metóda forward() odhaduje aktivácie na každej vrstve iteráciou cez všetky odchýlky a váhy v sieti. Na každom neuróne sa vstupy, čiže výstupy predchádzajúcich uzlov vynásobia príslušnými váhami spojení a následne sa sčítajú. Na záver sa aplikuje aktivačná funkcia neurónu. Vstup metódy forward() je trénovacia množina X_train.
Ako aktivačnú funkciu využijeme funkciu ReLu (Rectified linear unit), čiže po našom Rektifikovaná lineárna jednotka
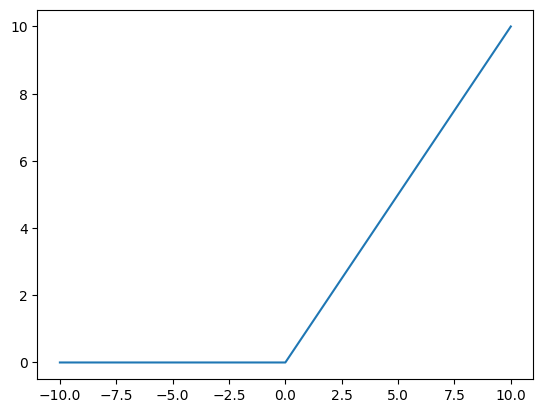
V oblasti kladných čísel je výstup lineárnou funkciou vstupu, pre záporné hodnoty je výstup nula.
Funkciu F.relu() by sme mohli nahradiť kódom
ReLu je najobľúbenejšia aktivačná funkcia na trénovanie konvolučných vrstiev a modelov hlbokého učenia, predovšetkým pre výpočtovú jednoduchosť a tiež preto že neurónová sieť sa dá jednoduchšie optimalizovať, keď je jej správanie lineárne alebo takmer lineárne.
Pri inicializácii modelu neurónovej siete použijeme ako váhové koeficienty náhodné čísla. Počas tréningu sa potom tieto hodnoty koeficientov budú postupne spresňovať
Vypíšeme parametre modelu
Model máme definovaný. Teraz treba špecifikovať, čo je cieľom trénovania. Potrebujeme aby model neurónovej siete produkoval výstup, ktorý je čo najbližšie realite. Trénovanie neurónovej má za cieľ nájsť najlepšiu sadu váh na mapovanie vstupov. Stratovú funkciu používame ako metriku na meranie „vzdialenosti“ predikcie od reality.
Nakoľko sa jedná o problém binárnej klasifikácie, použijeme binárnu krížovú entropiu. Taktiež potrebujeme optimalizátor. Je to algoritmus na progresívne nastavenie váh modelu, aby ste dosiahli lepší výstup. Na výber je veľa optimalizátorov a v tomto príklade je použitý Adam. Táto populárna verzia gradientového klesania sa dokáže automaticky vyladiť a poskytuje dobré výsledky v širokej škále problémov. Aby optimalizátor vedel, čo má optimalizovať, odovzdáme mu parametre vytvoreného modelu a definujeme rýchlosť učenia, v našom prípade lr=0,01
Trénovanie neurónovej siete
Definovali sme model, stratovú funkciu aj optimalizátor. Všetko je pripravené na trénovanie spustením modelu na množine trénovacích údajov. Neurónovú sieť trénujeme za účelom úpravy jej parametrov. Stratová funkcia vypočíta, aké nepresné boli predpovede v porovnaní s základnou pravdivostnou hodnotou pre danú množinu vstupov. Veľká nepresnosť znamená, že predpoveď siete sa líši od základnej pravdy, zatiaľ čo malá nepresnosť znamená, že predpoveď siete je podobná základnej pravde.Tréning modelu neurónovej siete prebieha v iteráciách nazývaných aj epochy a pri väčšom objeme údajov v dávkach.
Počas epochy sa modelu odovzdá celá množina trénovacích údajov. Dávka je jedna alebo viac vzoriek odovzdaných do modelu, z ktorých sa pre jednu iteráciu vykoná algoritmus zostupu gradientu
Jednoducho povedané, množina údajov sa rozdelí na dávky a jednotlivé dávky sa jedna po druhej odovzdávajú modelu prostredníctvom tréningovej slučky. Po vyčerpaní všetkých dávok je ukončená jedna epocha. Potom sa začína druhá epocha s rovnakou množinou údajov, pričom sa model vylepšuje. Tento proces sa opakuje, kým nie sme spokojní s výstupom modelu.
Veľkosť dávky je obmedzená pamäťou systému. Počet požadovaných výpočtov je tiež lineárne úmerný veľkosti dávky. Celkový počet dávok v mnohých epochách udáva, koľkokrát spustíte zostup gradientu na spresnenie modelu. Je to kompromis. Chceme viac iterácií pre gradientový zostup, aby sme mohli vytvoriť lepší model, ale zároveň nechceme, aby trénovanie trvalo príliš dlho. Počet epoch a veľkosť dávky je možné zvoliť experimentálne metódou pokus-omyl. Začneme 800 epochami. Výpis budeme robiť po stanovenom počte iterácií
Našim cieľom je nájdenie čo najlepších váh na vykonanie úlohy. V procese optimalizácie hľadáme váhy, ktoré minimalizujú funkciu straty, alebo priemernú hodnotu funkcie straty. V každej iterácii vykonáme jeden krok k vyriešeniu problému optimalizácie. Optimalizátor na základe stratovej funkcie určuje, ako a ako veľmi by sa mal každý parameter zmeniť.
Cieľom trénovania modelu je zabezpečiť, aby sa neurónová sieť naučila čo najlepšie mapovať vstupné údaje na výstupnú klasifikáciu. Nebude to dokonalé a chyby sú nevyhnutné. Množstvo chýb sa postupne zníži v neskorších epochách, ale nakoniec sa vyrovná. Dosiahne sa takzvaná modelová konvergencia.
Pre názornosť vykreslíme graf hodnôt stratovej funkcie
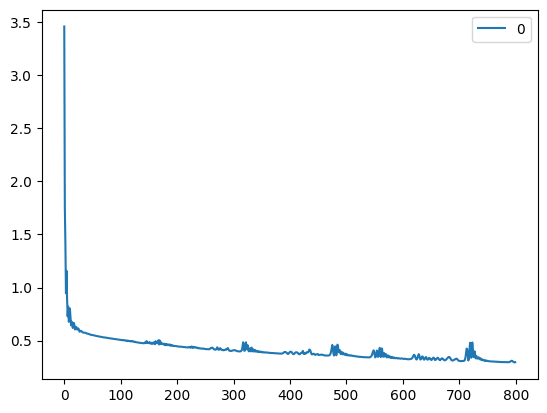
Teraz vyskúšame ako bude algoritmus predikcie fungovať na nových údajoch. Preto sme údaje rozdelili na trénovacie a testovacie. Testovacie údaje náš model nepozná. Naša testovacia množina má 154 záznamov (20 % zo všetkých údajov)
Vygenerujeme predpovede pre testovacie údaje. Uložíme ich do poľa predikcie a pre zaujímavosť aj priebežne vypíšeme
Aby sme si urobili predstavu o presnosti predpovedí, vytvoríme maticu nazývanú v originálnej terminológii Confusion Matrix. Matica obsahuje štyri údaje.
|
Správne pozitívna identifikácia |
Nesprávne pozitívna identifikácia |
|
Nesprávne negatívna identifikácia |
Správne negatívna identifikácia |
Pozitívna identifikácia je v prípade ak model predikoval, že človek dostane cukrovku. Správna je vtedy ak ju do piatich rokov skutočne dostane
Negatívna identifikácia je v prípade ak model predikoval, že človek cukrovku nedostane. Správna je vtedy ak ju do piatich rokov skutočne nedostane
Maticu Confusion Matrix môžeme názorne vykresliť pomocou knižnice Seaborn určenej na vizualizáciu štatistických údajov
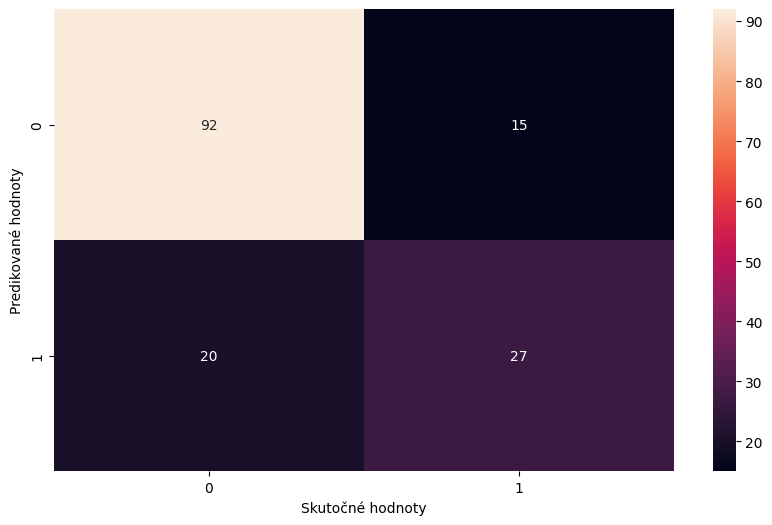
Môžeme tiež vypočítať skóre presnosti modelu
Model samozrejme môžeme použiť aj na predikciu priamo zadaných hodnôt. V tomto prípade sa jedná o hodnoty zo zdravotných záznamov, takže ako laici ich nevieme zadať spamäti. Pomôžeme si tým, že si necháme vypísať hodnoty z prvého záznamu a trochu ich upravíme, zmeníme vek, počet tehotenstiev a podobne
Upravené hodnoty
Pole zadaných hodnôt je potrebné konvertovať na tenzor
Keď už máme importovanú knižnicu seaborn, využijeme to na zobrazenie matice grafov vzájomných závislostí jednotlivých parametrov. Pre lepšiu názornosť zmeníme hodnoty výstupu, čiže atribútu Outcome z 1 a 0 na textové Áno a Nie
Vykreslenie matice grafov
sb.pairplot(df,hue="Outcome")
Pre zaujímavosťešte kód na uloženie modelu do súboru
Načítanie modelu zo súboru
Zobrazit Galériu