ML v Pythone 9 – trénovanie neurónu
V predchádzajúcej časti sme ukázali rozpoznávanie obrazu pomocou už natrénovanej neurónovej siete ResNet-50. V deviatej časti ukážeme ako sa trénujú neuróny umelej neurónovej siete. Bude to trochu dlhšie, nechceli sme túto problematiku rozdeľovať do viacerých dielov
Postup vytvorenia príkladov je v krátkom videu
Neurónové siete
Simulujú štruktúru ľudského mozgu, ktorý sa od detstva postupne učí, získava poznatky z množiny podnetov z okolitého sveta. Podobne aj neurónové siete získavajú poznatky z množiny vstupov a na základe nich dolaďujú svoje parametre modelu vzhľadom na nové znalostí. Spracovanie pomocou neurónových sietí funguje podobne ako ľudský mozog na princípe rozpoznávania vzorov a minimalizácie chýb. Tento proces si môžete predstaviť ako prijímanie informácií a poučenie sa z každej skúsenosti tak aby boli nájdené v údajoch určité schémy. Neurónovú sieť tvoria uzly usporiadané do vrstiev. Umelý neurón je funkcia, ktorá prijíma vstupy od ostatných neurónov, tieto vstupy sú vynásobené takzvanými váhami, takto získané hodnoty sa sčítajú a výsledok je odovzdaný aktivačnej funkcii. Výstup aktivačnej funkcie je výstupom neurónu.
Perceptrón
Je neurón určený na zaradenie prípadov do dvoch tried. Napríklad či na obrázku je, alebo nie je mačka. Je to algoritmus, ktorý poskytuje klasifikovaný výstup, čiže rozhoduje či niečo určené množinou vstupov je pravdivé alebo nepravdivé. Zložitejšie povedané je to model neurónu, ktorý prijíma vstupné signály nie priamo, ale cez synaptické váhy tvoriace váhový vektor. Zložky vstupného vektora môžu nadobúdať reálne alebo binárne hodnoty, napríklad obrázok zakódovaný ako pole, či viacrozmerný vektor, čiže tenzor. Zložky váhového vektora, ktoré definujú dôležitosť údajov z jednotlivých vstupov sú reálne čísla. Na vstup perceptronu sa v konečnom dôsledku dostane takzvaná vážená suma, čo je súčet hodnôt jednotlivých vstupov vynásobený váhovým vektorom. Táto hodnota sa porovná s takzvanou prahovou hodnotou. Ak ju vážená suma prekročí, výsledok rozhodovania bude kladný, v opačnom prípade záporný. Napríklad ak vážená suma, trebárs pravdepodobnosť toho, že na obrázku je konkrétny objekt, napríklad mačka je 0.4 a predpojatosť modelu (bias) v tomto príklade sme ju nazvali prahová hodnota je 0.5, tak na výstupe perceptrónu bude nula, čiže na obrázku zrejme mačka nie je. To samozrejme neznamená že tam naozaj nie je, môže byť napríklad v neobvyklej polohe.
Tak ako rôzni ľudia reagujú na rôzne podnety rôzne, tak aj rovnaké podnety privedené na vstup dvoch rôznych perceptrónov môžu byť a aj budú rôzne. Analógiou môžu byť dve veľmi malé deti, ktoré sa ešte len učia poznávať svet okolo seba. Jedno môže povedať, že na obrázku je mačka, a druhé, že to mačka nie je. Technokraticky povedané výsledkom je v prvom prípade pozitívna a v druhom prípade negatívna reakcia na rovnaký podnet. Takže aj dva perceptróny, ktoré majú na vstupe rovnaké podnety môžu dôjsť k rôznym záverom. Jeden môže vyhodnotiť, že na obrázku je pes, druhý, že je to mačka.
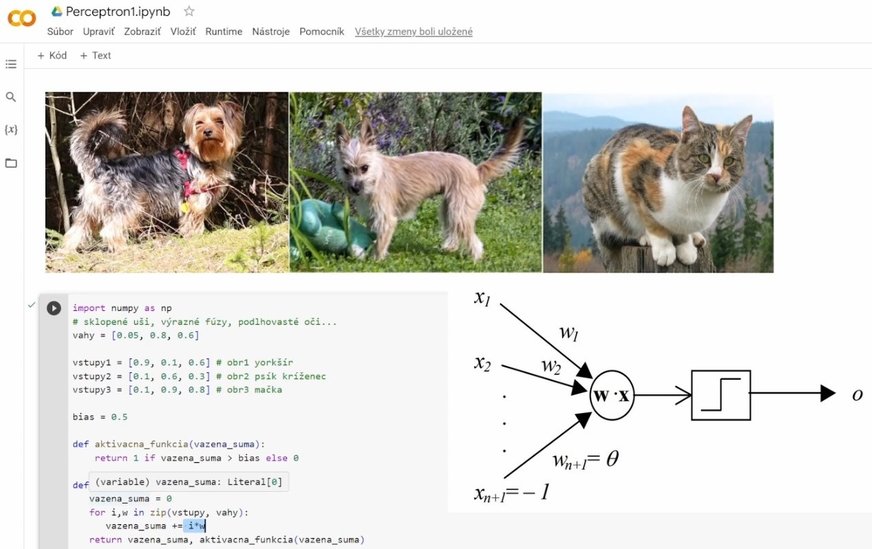
Ukážeme to na jednoduchom príklade kde budú vstupy a váhy zadané ako konštanty. Mohol by to byť perceptrón, ktorého úlohou je podieľať sa na rozhodnutí, či zviera na obrázku je, alebo nie je mačka. Nám je to okamžite jasné, ale perceptrón to musí zistiť. Príklad môžete realizovať buď v online prostredí Google Colaboratory, alebo lokálne v prostredí Jupyter Notebook, ktoré je súčasťou platformy Anaconda.

Aby bol príklad jednoduchý zrozumiteľný a trochu aj reálny, použijeme pre každý prípad tri vstupy, ktoré budú udávať, či objekt na obrázku má:
- sklopené uši
- výrazné fúzy
- elipsovité oči
Vstupy, ktoré by inak pochádzali z ďalších uzlov neurónovej siete budeme zadávať ručne, podľa toho ako na stupnici od 0 po 1 objekt spĺňa príslušné kritérium.
Empiricky sú definované aj váhové koeficienty
- sklopené uši (má máloktorá možno žiadna mačka) – 0.02
- výrazné fúzy (charakteristický znak mačky) – 0,8
- elipsovité oči (charakteristický znak mačky ) – 0.6
Váhový koeficient môže byť aj záporné číslo, my sme dali veľmi malé kladné. Uvidíme ako sa tieto koeficienty neskôr v procese optimalizácie zmenia. Zdôrazňujeme, že váhové koeficienty sme určili odhadom.
Prvý vstup nášho príkladu udáva s akou pravdepodobnosťou bolo rozpoznané, že zviera na obrázku má sklopené uši. Yorkšír na prvom obrázku sklopené uši má, takže vstupná hodnota by mohla byť 0.9.
Druhý vstup udáva, či zviera na obrázku má fúzy. Nič také však na prvom obrázku nebolo rozpoznané takže vstup má hodnotu 0.1,
Psík na obrázku má síce oči skôr okrúhle, avšak nie je ostrihaný, takže vyzerajú ako podlhovasté. Vstup má hodnotu 0.6
Výstup 0 v prvom prípade je správny, o tom že to nie je mačka, rozhodla skutočnosť že na obrázku boli rozpoznané sklopené uši a zviera nemalo rozpoznateľné fúzy. Zároveň výsledok je tesný, a to kvôli neostrihaným očiam, ktoré vyzerajú ako podlhovasté.
V druhom prípade je výsledok nesprávny výstup 1 indikuje, že na obrázku by mala byť mačka. Tento výstup je nesprávny na obrázku je tiež psík – kríženec so špicatými ušami, rozpoznateľnými fúzami a tentoraz s okrúhlymi (ostrihanými) očami
Tretia množina vstupov je pre obrázok mačky so všetkými charakteristickými vlastnosťami a výstup je 1, čiže správny
V našom príklade bol jeden omyl, keď perceptrón nesprávne určil, že na obrázku je mačka, aj keď tam mačka nebola. Takýto mechanizmus nás samozrejme nemôže uspokojiť. Aby perceptrón fungoval s vyššou presnosťou a dopúšťal sa čo najmenšieho počtu chýb, je potrebné upraviť váhové koeficienty.
Doteraz získané výsledky sme zhrnuli do tabuľky a pridali sme aj hodnotu cieľa, čiže očakávaného výstupu korešpondujúceho so skutočnosťou.
|
objekt
|
V1
|
V2
|
V3
|
V_suma
|
Výstup
|
Očakávaný výstup
|
|
yorkšír
|
0.9
|
0.1
|
0.6
|
0,485
|
0
|
0
|
|
psík kríženec
|
0.9
|
0.6
|
0.3
|
0.665
|
1
|
0
|
|
mačka
|
0.1
|
0.9
|
0.8
|
1,205
|
1
|
1
|
Výstup je preto potrebné upraviť, alebo lepšie povedané upravovať dovtedy kým sa výstupy nezhodujú s cieľom. Najskôr potrebujeme určiť ako ďaleko sme od stanoveného cieľa. Na tento účel sa používa stratová funkcia, nazývaná aj chybová, v originálnej terminológii Loss Error Function.
Predpokladajme situáciu že máme definované vstupy, váhy a stanovené ciele, pričom predpoveď, čiže výstup perceptronu sa v niektorých prípadoch s predpokladaným cieľom zhoduje a v niektorých sa nezhoduje.
Chyba = – (vystup * log(vazena_suma) + (1 - vystup) * log(1- vazena_suma))
Kde výstup z perceptrónu môže nadobúdať hodnoty 0, alebo 1. Ak je výstup 0 tak prvá časť rovnice bude tiež 0. Ak je výstup 1, bude 0 aj druhý člen súčtu.
Pre vstupy so správne rozpoznaným obrázkom na ktorom nie je mačka
Chyba = – (0 * log(0.485) + (1 - 0) * log(1 - 0.485)) = - log(0,515) = -( -0,29) = 0.29
Pre ďalšie vstupy (psík kríženec) a správny výstup
Chyba = – (1 * log(0.665) + (1 - 1) * log(1- 0.665)) = -log(0.335) = 0,47
Pre ďalšie vstupy (mačka) a správny výstup
Chyba = – log(1,205) = 0.08
Samozrejme tieto hodnoty by nám spočítal kód v Pythone na niekoľko riadkov, no sme chceli ukázať ako sa to počíta. Napokon o nič neprídete, implementácia vzorca pre výpočet chyby bude v ďalšom príklade.
Ak sa predpoveď zhoduje s cieľom, chybová hodnota bude nízka. Takže doplňme našu tabuľku o výsledky
|
objekt
|
V1
|
V2
|
V3
|
V_suma
|
Výstup
|
Očakávaný výstup
|
chyba
|
|
yorkšír
|
0.9
|
0.1
|
0.6
|
0,485
|
0
|
0
|
0.29
|
|
psík kríženec
|
0.9
|
0.6
|
0.3
|
0.665
|
1
|
0
|
0.47
|
|
mačka
|
0.1
|
0.9
|
0.8
|
1,205
|
1
|
1
|
0.08
|
Priemerná chyba 0.28
Priemerná chyba, vyjadrujúca chybovosť modelu, v našom prípade 0.28 nám určuje ako ďaleko sú naše výstupy od vytýčeného cieľa, čiže vzdialenosť medzi výstupom a jeho cieľom.
Mimochodom mohli sme hneď na začiatku uviesť tento pre matematika jednoduchý vzorec
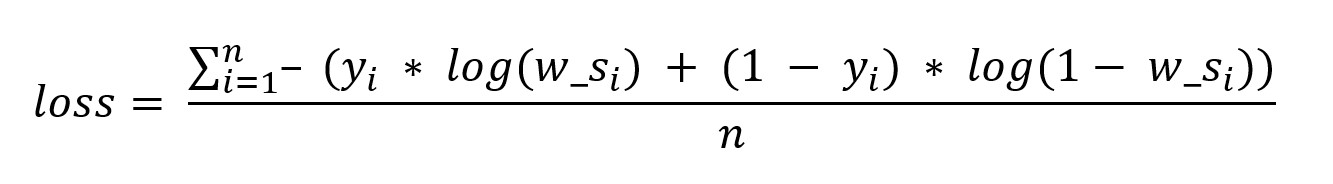
Radšej sme zvolili popis výpočtu krok za krokom aby sme vzorcom neodradili ľudí, ktorí si potrebujú problematiku zopakovať.
Gradientný zostup
Za týmto názvom sa v podstate skrýva aktualizácia váhových koeficientov modelu tak aby predpovede optimalizovaného modelu boli najpresnejšie, alebo inak povedané aby mali čo najmenšiu chybovosť. V skriptách by teraz nasledovali zložité vzorce s mnohými gréckymi písmenami a matematickými symbolmi. Princíp gradientného zostupu skúsime vysvetliť jednoduchšie a čo najnázornejšie.
Perceptrón ako ho zatiaľ poznáme poskytuje binárny výstup, čiže pravdepodobnosť predpovede, je buď 0, alebo 1. Laicky povedané, v predchádzajúcom prípade na obrázku buď je mačka, alebo to mačka nie je. S takýmto „hrubým“ výstupom by sme však nedokázali model aktualizovať. Preto potrebujeme predpoveď v intenciách klasickej pravdepodobnosti. Čiže v našom prípade s akou pravdepodobnosťou je na obrázku mačka. Váženú sumu sme porovnávali s prahovou hodnotou označenou bias. Toto anglické slovo by sme mohli preložiť ako predpojatosť, alebo zaujatosť
Preto musíme aktivačnú funkciu zmeniť tak aby na výstupe nevracala binárne hodnoty 0 a 1, ale pravdepodobnosť v rozsahu 0.0 – 1, napríklad 0.35, čo znamená 35 %. Na tento účel využijeme funkciu sigmoid , ktorej vzorec je
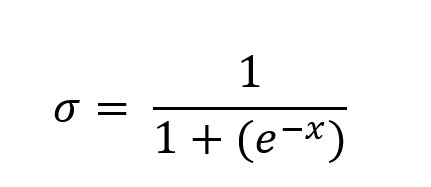
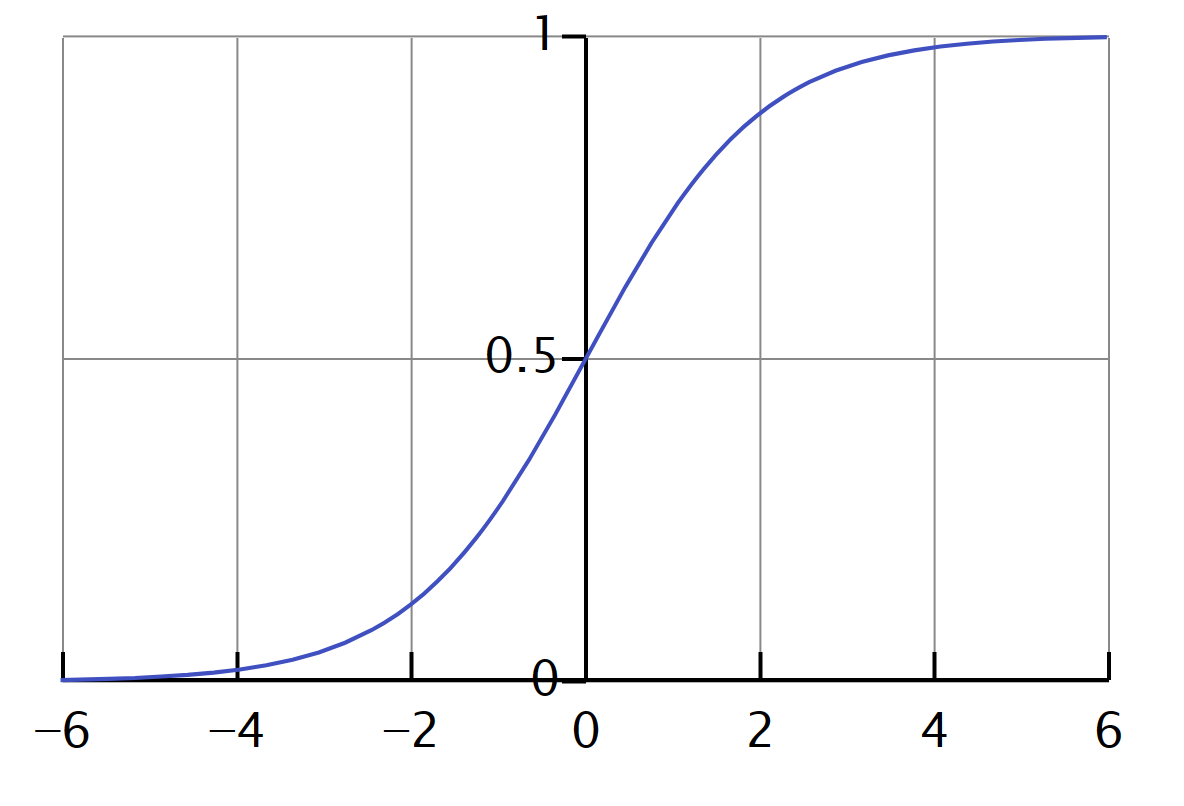
kde e je základ prirodzených logaritmov 2.71828... Priebeh funkcie sigmoid je krivka v tvare S. Parameter x bude v našom prípade vážená suma.
Na ilustráciu si môžeme si nechať vykresliť graf tejto funkcie pre zadaný rozsah hodnôt
Vážené sumy vypočítame sčítaním výsledkov násobenia na čo nám vynikajúco poslúži funkcia numpy.dot()
Do funkcie na výpočet predpovede potrebujeme zahrnúť aj bias (predpojatosť), ktorý jednoducho pripočítame k váženým sumám
Predpovede už teda nebudú len vstupy vynásobené váhami, ale pripočíta sa k ním aj predpojatosť.
V procese optimalizácie nazývanom gradientný zostup postupne vo viacerých krokoch vypočítame nové, lepšie váhové koeficienty pre jednotlivé vstupy.
Prepísané do zrozumiteľnejšej podoby
Nová_váha = pôvodná_váha + rýchlost_ucenia *(ciel - predpoved) * vstup
Aktualizovaný bias vypočítame podľa vzorca
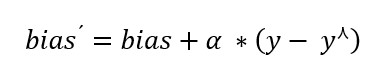
Čiže
Nový_bias = pôvodný_bia + rýchlost_ucenia *(ciel - predpoved)
Rýchlosť učenia je potrebné nastaviť na malú hodnotu, napríklad 0,1, 0,01 prípadne aj menšiu aby sa jednotlivé váhy aktualizovali nie skokovo, ale postupne, pretože v každom kroku ich smenu ovplyvňuje viac faktorov. Pri veľkej zmene by mohol náš model ľudovo povedané niečo dôležité nepostrehnúť.
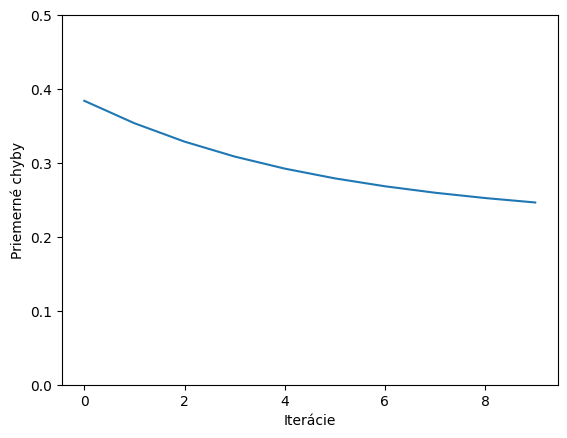
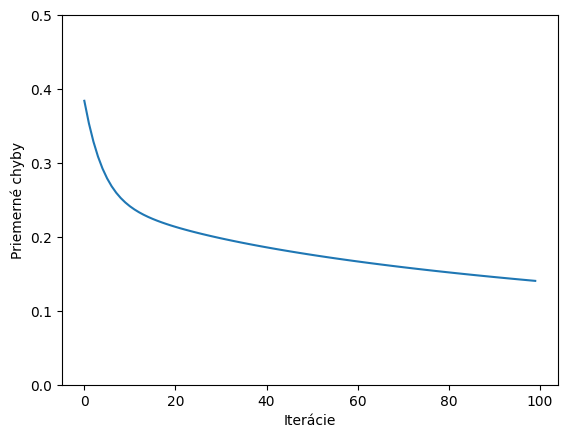
Upravíme kód aby nám vykreslil graf chybovej funkcie, pričom na osi X sú iterácie
Váhy: ['-0.47', '0.66', '0.34'] Bias: -0.351 Loss: 0.247
Výsledky pre 10 iterácií
Váhy: ['-0.47', '0.66', '0.34'] Bias: -0.351 Loss: 0.247
Výsledky pre 100 iterácií
Váhy: ['-1.79', '1.69', '1.37'] Bias: -1.744 Loss: 0.140
Výsledky pre 1000 iterácií
Váhy: ['-3.63', '4.15', '6.68'] Bias: -6.291 Loss: 0.029
 |
 |
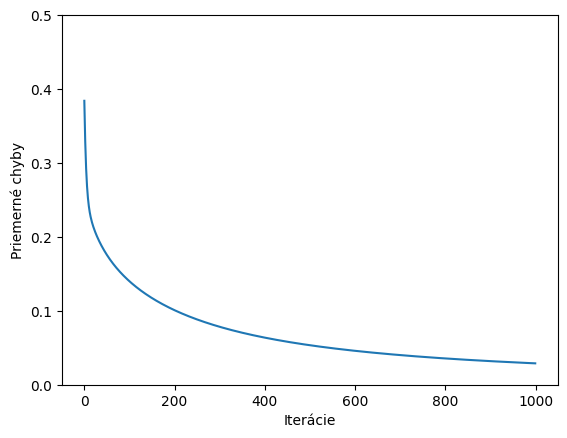 |
Samozrejme pre trénovanie na troch prípadoch viac ako 10 iterácií nemá žiadny praktický zmysel
Pre zaujímavosť dosadíme váhy po 10-tich iteráciách do kódu perceptronu
Predpovede, či zviera na obrázku je, alebo nie je mačka sú tentoraz správne
Rekapitulácia doterajších dielov
Strojové učenie v Pythone 1 – prostredie Google Colab
Strojové učenie v Pythone 2 – knižnica Pandas na prácu s údajmi
ML v Pythone 3 – export a import údajov vo formáte CSV a Excel
Strojové učenie v Pythone 4 – práca s údajmi
ML v Pythone 5 – vizualizácia údajov pomocou grafov
ML v Pythone 6 – animované grafy a ich export ako video
ML v Pythone 7 – Využitie grafickej karty NVIDIA na výpočtovo náročné úlohy
ML v Pythone 8 – príklad rozpoznávanie obrazu
Zobrazit Galériu