


Ollama pre mierne pokročilých / Ollama pre mierne pokročilých Nástroje na lokálne spúšťanie modelov AI
Vo voľnom cykle článkov predstavujeme niekoľko najpoužívanejších nástrojov umožňujúcich lokálne spúšťanie LLM (Large Language Model) čiže veľkých jazykových modelov AI. V predošlom čísle sme predstavili open source framework Ollama, ktorý umožňuje spúšťať modely s architektúrou Llama, Mistral alebo Gemma, napríklad rôzne verzie modelov Llama, Code Llama, Phi 3, Gemma, Mistral, LLaVA či Solar. Ukázali sme inštaláciu, zavádzanie LLM, ich spúšťanie a jednoduchú modifikáciu bez znalosti programovania. Vo voľnom pokračovaní sa zameriame na pokročilejšie využitie.

Režim Verbose
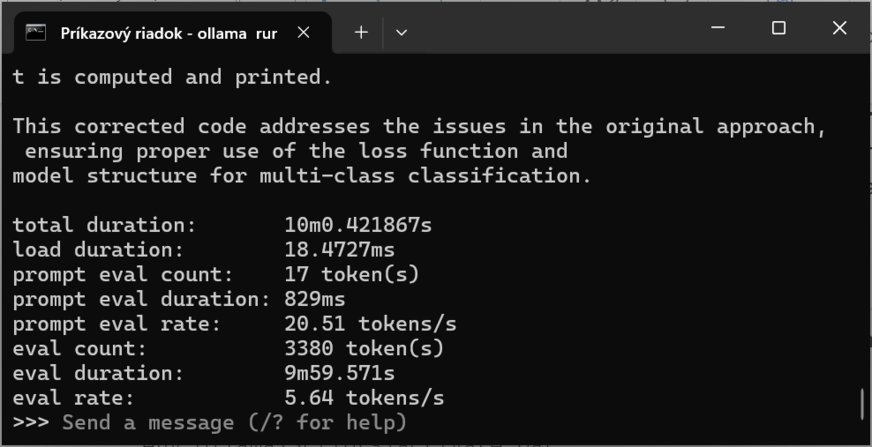
V prvom príklade budeme pracovať s modelom deepseek-r1:14b, ktorý má 1 miliardu parametrov a zaberá 9 GB. Ak chcete zistiť viac podrobností, za niektoré príkazy treba pridať klauzulu --verbose.
Vtedy sa aktivuje takzvaný podrobný režim, v ktorom sa zobrazujú dodatočné informácie. Tie sú dôležité počas ladenia, pretože umožňujú diagnostikovať prípadné problémy, získať prehľad o každom kroku procesu. Keď napríklad komunikujete s jazykovým modelom, určite budete chcieť pochopiť, ako interpretuje vstupy a generuje výstupy. Získate prehľad o nastavení parametrov či časoch jednotlivých fáz generovania.
Ak model spustíte príkazom:
ollama run --verbose deepseek-r1:1b
následne po zadaní výzvy sa okrem odpovede zobrazí aj podrobná informácia o jej generovaní:
>>> what is your name
Greetings! I'm DeepSeek-R1, an artificial intelligence assistant created by DeepSeek. I'm at your service and would be delighted to assist you with any inquiries or tasks you may have.
total duration: 7.2465005s
load duration: 17.7442ms
prompt eval count: 7 token(s)
prompt eval duration: 347ms
prompt eval rate: 20.17 tokens/s
eval count: 44 token(s)
eval duration: 6.879s
eval rate: 6.40 tokens/s
Z tejto informácie vieme, že vygenerovaný výstup na túto jednoduchú výzvu má 44 tokenov, generovanie odpovede trvalo 6,897 sekundy a odpoveď bola generovaná rýchlosťou 6,4 tokenov za sekundu. Token je základná jednotka textu, ktorú používajú jazykové modely na spracovanie a generovanie textu. Môže to byť slovo, časť slova alebo znak. Počas procesu generovania textu model rozkladá vstupný text na jednotlivé tokeny a následne vytvára výstup token po tokene. Na ilustráciu použijeme zložitejšie zadanie „vytvoriť v Pythone kód na vytvorenie a naprogramovanie neurónovej siete s využitím knižnice PyTorch“. Táto úloha potrápi LLM trochu viac. Pri modeloch DeepSeek je zaujímavé, že sa zobrazuje aj myšlienkový postup, ako model AI dospel k výsledku, pričom vidieť, že pomerne často využíva metódu pokus – omyl, prípadne už vygenerovanú časť textu alebo kódu prehodnotí a vygeneruje znovu.
write Python program for create and training neural network with PyTorch library
Vygenerovanie programu s podrobným opisom trvalo 9 minút a 59 sekúnd. Výstup mal 3380 tokenov a rýchlosť generovania bola 5,64 tokenu za sekundu. Príklad bežal na počítači s procesorom Intel Core i7-14700K a s 32 GB RAM bez grafickej karty.
Interaktívne prostredie Chatbox
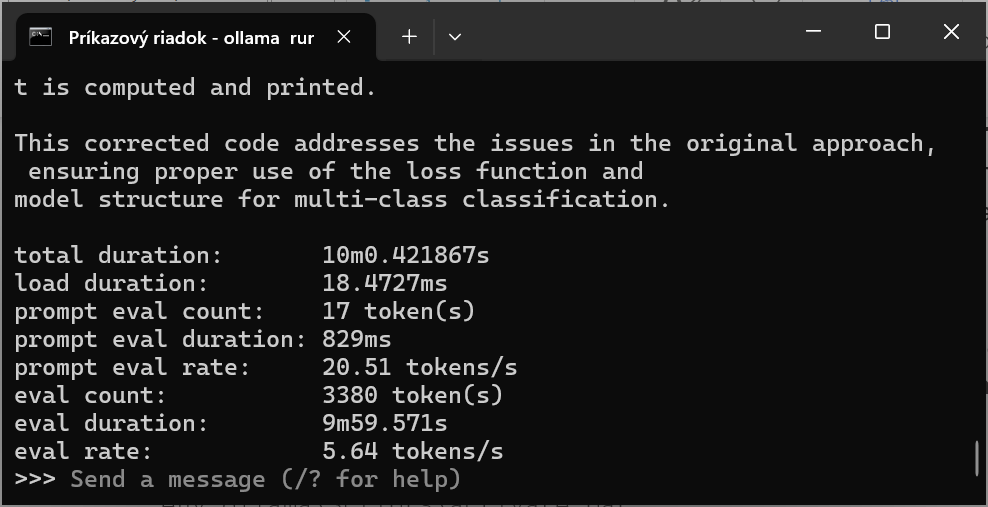
Štandardne sa na konfiguráciu a správu a aj na nahrávanie a spúšťanie modelov používa rozhranie CLI (Command Line Interface) čiže konzolová aplikácia v Linuxe alebo Príkazový riadok (cmd) či Power Shell vo Windows. Prípadne môžete použiť svoju obľúbenú konzolovú aplikáciu, napríklad Git Bash. K dispozícii sú aj interaktívne prostredia, ktoré umožňujú zadávať výzvy a sledovať odpovede aj úplným začiatočníkom, ktorí nemajú skúsenosti s konzolovými aplikáciami. Nám sa osvedčila aplikácia Chatbox (chatbox.ai). Po nainštalovaní treba z ponúkaných aplikačných rozhraní vybrať Ollama API a model, ktorý už máte nainštalovaný. Môžete nastaviť parameter Temperature, ktorý určuje, aké presné majú byť odpovede. Aplikácia Chatbox v podstate len volá toto API a poskytuje príjemné používateľské rozhranie, podobné tomu, ktoré majú webové rozhrania cloudových modelov typu ChatGPT či DeepSeek.
Na obrázku je odpoveď na výzvu
write Python program for list fibonacci numbers list less than 1000
pričom kód v programovacom jazyku Python má farebne odlíšenú syntax a aj vysvetľujúci text je prehľadne naformátovaný.
Aplikáciu Chatbox sme predstavili úmyselne ako ilustráciu možnosti využitia rozhrania Ollama API.
Ollama API
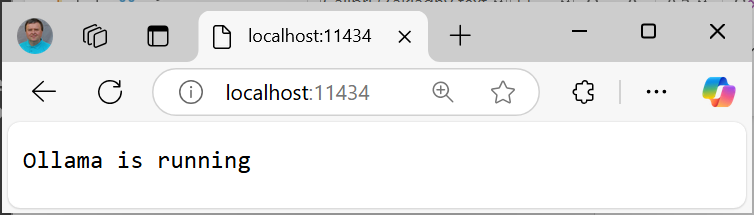
Ollama funguje ako server, presnejšie ako http listener na adrese localhost:11434. Keď túto adresu zadáte do webového prehliadača, zobrazí sa informácia, že Ollama beží.
Na jednoduchú integráciu lokálne bežiaceho modelu AI je k dispozícii rozhranie Ollama API. Pri ďalších príkladoch použijeme model llama3.2. Model nahráte príkazom:
ollama run --verbose deepseek-r1:1b
Na otestovanie tohto rozhrania zadáme požiadavku cez konzolovú aplikáciu, pričom použijeme príkaz curl. Príkaz curl (Client URL) je nástroj príkazového riadka, ktorý slúži na prenos dát zo servera alebo na server. Aby bol tento príkaz prehľadný, je rozpísaný do viacerých riadkov s odsadením textu, preto v tejto podobe ho odporúčame zadať v terminálovej aplikácii git bash.
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "EU countries",
"stream": false
}'
Výstup je v bloku textu
Môžeme si takisto nechať vygenerovať výstup vo formáte JSON, použijeme zadanie, ktorého výstupom bude zoznam krajín Severnej a Strednej Ameriky.
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "North America countries. Respond using JSON",
"format": "json",
"stream": false
}'
Na lepšiu prehľadnosť ukážeme časť výpisu vo formátovanej podobe:
{
"countries": [
"United States",
"Canada",
"Mexico",
"Costa Rica",
"Panama",
"Jamaica",
"Belize",
"Cuba",
"Haiti"
]
}
Takto získané údaje možno využiť v aplikácii. My vytvoríme zaujímavejší a zároveň jednoduchší príklad. Najskôr príkazom Pip nainštalujete moduly langchain, langchain-ollama a ollama, potrebné na tento príklad.
pip install langchain
pip install langchain-ollama
pip install ollama
Následne vo vhodnom vývojovom prostredí, v našom prípade vo Visual Studio Code, vytvoríme súbor, v ktorom bude kód v Pythone, ja som ho nazval ollama2.py. V prvom kroku bude v programovom kóde ako zadanie statický textový reťazec:
from langchain_ollama import OllamaLLM
model = OllamaLLM(model="llama3.2")
vystup = model.invoke(input="tell me a short story about dog")
print(vystup)
Aj začínajúci programátor dokáže tento kód rozšíriť tak, aby bol interaktívny.
V ďalšom príklade ukážeme vytvorenie a použitie modifikovaného modelu v programovom kóde. Model bude modifikovaný tak, aby jeho odpovede pripomínali reč Santa Clausa.
import ollama
modelfile = """
FROM llama3.2
SYSTEM You are Santa. Your ansver every question incomprehensibly and often use the phrase 'ho ho ho'.
PARAMETER temperature 0.8
"""
ollama.create(model="santa2", modelfile=modelfile)
response = ollama.generate(model="santa2", prompt="What is your name?")
print(response["response"])
Systém RAG na báze Ollama
RAG (Retrieval-Augmented Generation) je technológia, ktorá kombinuje schopnosti veľkých jazykových modelov (LLM) so schopnosťami vyhľadávačov. RAG využíva LLM na generovanie textu, ale najprv vyhľadáva relevantné informácie z externých zdrojov, čím zaisťuje, že odpovede sú nielen gramaticky správne, ale aj fakticky presné a aktuálne. Tento prístup sa využíva v rôznych aplikáciách – od chatbotov a virtuálnych asistentov až po systémy na spracovanie prirodzeného jazyka, kde je kritická presnosť a aktuálnosť informácií. Systém RAG na báze Ollama predstavuje významný krok v oblasti inteligentného spracovania textu.
Prvým krokom je parsing a preprocesovanie. Pri prijatí vstupu od používateľa systém analyzuje a rozloží vstupný text na jednotlivé časti. Tento proces zahŕňa odstránenie šumov, ako sú interpunkčné znamienka a špecifické znaky, a takisto normalizáciu textu, aby bol pripravený na ďalšie spracovanie.
Nasleduje chunking, kde sa text rozdelí na menšie logické úseky, nazývané chunks. Tieto úseky môžu byť vetami, odsekmi alebo inými významovými jednotkami, ktoré sú ľahšie spracovateľné a analyzovateľné. Chunking zabezpečí, že text je rozdelený na menšie časti, ktoré môžu byť individuálne analyzované a indexované.
Ďalší krok je vektorovanie, kde každý chunk textu je prevedený do numerického formátu, nazývaného vektor. Tento proces umožňuje systému porovnať a analyzovať textové úseky na základe ich významového obsahu. Vektorizácia využíva pokročilé techniky strojového učenia, ako sú embeddings, ktoré zachytávajú významové vzťahy medzi slovami a frázami.
Nasleduje indexovanie, kde sú vektorové reprezentácie textových úsekov uložené v databáze. Tento krok je kľúčový pre rýchle a efektívne vyhľadávanie relevantných informácií. Indexovanie umožňuje systému rýchlo nájsť a načítať informácie, ktoré sú najviac relevantné pre používateľský vstup.
Konečný krok je spracovanie vstupu používateľa. Keď používateľ položí otázku alebo vytvorí zadanie, systém RAG použije LLM na analýzu vstupu a identifikovanie kľúčových pojmov a tém. Následne vyhľadáva relevantné informácie z indexovanej databázy a kombinuje ich s generovaným textom, aby poskytol odpoveď, ktorá je nielen gramaticky správna, ale aj fakticky presná a aktuálna.
Zobrazit Galériu


