V predchádzajúcej časti sme ukázali vytvorenie neurónovej siete, ktorá predpovedala výskyt cukrovky u indiánskeho kmeňa. Príklad v tejto stati bude zameraný na analýzu vzoriek údajov z oblasti prírodných vied. Úlohou neurónovej siete bude rozlíšiť jedlé huby od húb nejedlých a jedovatých. Príklad je názorný. Vo videu je kompletný postup.
V príklade predikcie cukrovky u indiánov kmeňa Pima boli všetky atribúty spojité. Napríklad vyššia hodnota atribútu vek znamenala že osoba je staršia, vyššia hodnota BMI, že je obéznejšia, rovnako je to aj s hladinou cukru a podobne.
Diskrétne kategorizačné údaje takúto súvislosť nemajú. Napríklad huba môže mať klobúk zvonovitý, kužeľovitý, vypuklý, plochý, s hrbolčekom uprostred, avšak to sú len kategórie. Nemôžeme povedať, že plochý klobúk huby je väčší, menší, jedlejší jedovatejší, lepším horší ako zvonovitý, či vypuklý. Úlohou neurónovej siete bude odhaliť prípadné vzťahy medzi kategóriami. Napríklad poštové smerovacie čísla v adrese nemajú priamu súvislosť, ale podľa nich sa dá určiť, že niektoré adresy sú geograficky blízko seba, prípadne že ľudia, ktorí majú v adrese rovnaké smerovacie číslo majú podobný sociálno-ekonomický status a podobne.
Alebo iný príklad: pondelok a utorok sú dosť podobné dni, avšak sú v mnohých ohľadoch iné ako sobota, či nedeľa. Preto sa odporúča mesiac, rok, deň v týždni a niektoré ďalšie premenné za kategorizačné aj keď by sa mohli na prvý pohľad považovať za spojité. Pre premenné s relatívne malým počtom unikátnych hodnôt to často vedie k lepšiemu výsledku. Toto je jedno z dôležitých rozhodnutí, ktoré robí dátový vedec. Premenné reprezentované číslami s pohyblivou rádovou čiarkou ako takmer vždy považujeme za spojité.
Hoci sa môžeme rozhodnúť považovať spojité premenné za kategorizačné, opačne to neplatí: všetky premenné, ktoré sú kategorizačné, sa musia považovať za kategorizačné.
Popis vstupných údajov
Zdrojová databáza získaná z webu Department of Information and Computer Science University of California, Irvine CA. (http://archive.ics.uci.edu/ml/datasets/Mushroom ) pozostáva z dvoch textových súborov agaricus-lepiota.data a agaricus-lepiota.names Súbor agaricus-lepiota.data je klasickým súborom flat –file, kde sú jednotlivé atribúty oddelené čiarkami a jednotlivé záznamy sú oddelené prechodom na nový riadok Súbor obsahuje 8124 riadkov. Vo výpise je len ilustračná ukážka
p,x,s,n,t,p,f,c,n,k,e,e,s,s,w,w,p,w,o,p,k,s,u
e,x,s,y,t,a,f,c,b,k,e,c,s,s,w,w,p,w,o,p,n,n,g
e,b,s,w,t,l,f,c,b,n,e,c,s,s,w,w,p,w,o,p,n,n,m
....
Legenda k takto usporiadanému CSV je v súbore agaricus-lepiota.names
Okrem informácie či je huba jedlá, alebo nie máme k dispozícii ešte 22 ďalších charakteristických vlastností pre každú hubu.
V príklade sú názvy atribútov preložené do češtiny
Pre rámcovú predstavu uvádzame skrátený fragment výpisu cieľovej tabuľky
id Pozivatelnost TvarKlobouku PovrchKlob BarvaKlob Ox.ZmenaBarvy Zapach ---- ------------------ ------------- ----------- ---------- -------------- -----------------1 nejedlá, jedovatá vypouklý hladký hnědá ano štiplavý, čpavý 3 jedlá zvonovitý hladký bílá ano anýzový 5 jedlá vypouklý hladký šedá ne žádný 7 jedlá zvonovitý hladký bílá ano po mandlích 9 nejedlá, jedovatá vypouklý šupinatý bílá ano štiplavý, čpavý 11 jedlá vypouklý šupinatý žlutá ano anýzový 13 jedlá zvonovitý hladký žlutá ano po mandlích 15 jedlá vypouklý vláknitý hnědá ne žádný 17 jedlá plochý vláknitý bílá ne žádný 19 nejedlá, jedovatá vypouklý šupinatý bílá ano štiplavý, čpavý 21 jedlá zvonovitý hladký žlutá ano po mandlích
Pre zaujímavosť celková štatistika zastúpenia jedlých a jedovatých húb v prezentovanej vzorke je nasledovná:
jedlé: 4208 (51.8%)
nejedlé a jedovaté: 3916 (48.2%)
spolu: 8124 húb
Na základe tabuľky pre učenie by podľa prezentovaných údajov dokázal vyvodiť len nejaký dobrý hubár, ktorý už má určité svoje poznatku a má ich do istej miery overené. Neurónová sieť žiadne poznatky nemá no môže ich na základe analýzy vzorky údajov získať.
Príklad budeme robiť v prostredí Google Coleboratory, takže súbor agaricus-lepiota.data premenujeme na agaricus-lepiota.data.csv uložíme na Disk Google, v našom prípade do priečinka ML Neuronova siet. Súbor sme premenovali preto, aby sme mohli štandardnými prehliadačmi zobraziť jeho obsah
Príprava údajov
Pri načítaní CSV súboru priradíme atribútom názvy. CSV súbor, ktorý nahrávame nemá v prvom stĺpci index, ale prvý atribút je požívateľnosť, takže index priradíme explicitne. Inak by bol za index považovaný prvý atribút, v našom prípade požívateľnosť.
Poznámka: pre názornosť načítame všetky atribúty, neskôr pre trénovanie neurónovej siete použijeme len najrelevantnejšie.
Pre lepšiu názornosť najskôr zredukujeme počet atribútov na šesť najrelevantnejších. Ale ktoré to sú? Skúsení hubári možno vedia. Ja som tieto údaje pred niekoľkými rokmi použil pre príklad dataminingu v Microsoft SQL Serveri 2012. Tam je k dispozícii nástroj, ktorý dokáže identifikovať, ktoré atribúty majú najvýraznejší vplyv na predikovaný atribút požívateľnosti. Je to: Zápach, FarbaVytrusu, FarbaRebrovania, TypPrstienka, PovrhNozkyPodPrstenom a PovrhNozkyNadPrstenom.
Definujeme kategorizačné atribúty a výstupný atribút
Neurónová sieť pracuje s číslami, takže potrebujeme transformovať textové reťazce na číselné hodnoty. Napríklad atribút Farba výtrusu môže nadobudnúť hodnoty:
Vypočítame počet výstupných dimenzií. Pre počet výstupných dimenzií vo všeobecnosti platí pravidlo nazývané Thumb rule. Počet výstupných dimenzií pre kategorizačné atribúty sa určuje podľa počtu vstupných dimenzií podľa vzorca
Výstupné_dimenzie = min(50, vstupné_dimenzie /2)
V prípade ak je výsledkom desatinné číslo počet výstupných dimenzií bude najbližšie vyššie celé číslo
Interpretácia vzorca v Pythone bude:
embedding_dim= [(x, min(50, (x + 1) // 2)) for x in kat_dims]
embedding_dim
---výpis---
[(9, 5), (9, 5), (12, 6), (5, 3), (4, 2), (4, 2)]
Prvá dimenzia má 9 vstupov a 5 výstupov, druhá dimenzia má tiež 9 vstupov a 5 výstupov, tretia dimenzia má 12 vstupov a 6 výstupov atď.
Definovanie neurónovej siete
Všetko máme pripravené, môžeme definovať model neurónovej siete. Neurónovú sieť definujeme ako triedu. Náš model bude jednoduchá dopredná neurónová sieť s dvoma skrytými vrstvami, vloženými vrstvami pre kategorické prvky a potrebnými vrstvami pre výpadky a dávkovú normalizáciu. Trieda nn.Module je základná trieda pre všetky neurónové siete v knižnici PyTorch. Náš model, ModelNS, bude podtriedou triedy nn.Module. V metóde __init__ našej triedy budeme inicializovať rôzne vrstvy, ktoré budú použité v modeli a metóda forward() definuje výpočty vykonávané v sieti.
Vysvetlíme parametre v konštruktore, čiže metóde __init__()
emb_dims: Zoznam dvoch prvkov n-tice - bude obsahovať dva prvky pre každý kategorizačný atribút. Prvý prvok n-tice udáva počet jedinečných hodnôt vlastností atribútu. Druhý prvok udáva rozmer vloženia (embedding_dim), ktorý sa má použiť pre tento atribút. V našom prípade to budú dimenzie
[(9, 5), (9, 5), (12, 6), (5, 3), (4, 2), (4, 2)]
output_size: celé číslo, hodnota konečného výstupu.
layers: zoznam celých čísel udávajúcich veľkosť každej lineárnej vrstvy.
p: Float (emb_dropout) výpadok, ktorý sa má použiť po vložených vrstvách. Je to pravdepodobnosť prvku, ktorý bude vynulovaný. Predvolená hodnota je 0,5
Najskôr vysvetlíme ako fungujú funkcie, ktoré použijeme pri definovaní neurónovej siete.
V konštruktore vytvoríme zoznam modulov, ktorých úlohou je prechádzať medzi dimenziami jednotlivých kategorizačných atribútov. Na vytvorenie modulov použijeme funkciu nn.Embedding(inp,out).
# --------------------------
# --- kód na vysvetlenie ---
# --------------------------
import torch
import torch.nn as nn
import torch.nn.functional as F
zoznam_modulov=nn.ModuleList([nn.Embedding(inp,out) for inp,out in embedding_dim])
zoznam_modulov
---výpis---
ModuleList(
(0-1): 2 x Embedding(9, 5)
(2): Embedding(12, 6)
(3): Embedding(5, 3)
(4-5): 2 x Embedding(4, 2)
)
Pre každý modul vytvoríme tenzory kategorizačných atribútov
Každý modul má v tenzore rovnaký počet prvkov ako výstupných atribútov. V našom prípade 5, 5, 6, 3, 2, 2, pretože rozmery pre naše kategorizačné atribúty sú
[(9, 5), (9, 5), (12, 6), (5, 3), (4, 2), (4, 2)]
V zozname modulov sú rovnaké vrstvy označené násobiteľom výskytu
ModuleList(
(0-1): 2 x Embedding(9, 5)
(2): Embedding(12, 6)
(3): Embedding(5, 3)
(4-5): 2 x Embedding(4, 2)
)
Na spojenie týchto tenzorov, ktoré majú rôzne dimenzie sa použije funkcia torch.cat().
Funkcia nn.Dropout() počas trénovania neurónovej siete náhodne vynuluje niektoré prvky vstupného tenzora s pravdepodobnosťou p s použitím vzoriek z Bernoulliho rozdelenia. Každý kanál sa vynuluje nezávisle pri každom doprednom volaní. Je to účinná technika na regularizáciu a zabránenie ko-adaptácii neurónov. Okrem toho sú počas trénovania výstupy škálované koeficientom
To znamená, že počas vyhodnocovania modul jednoducho vypočíta funkciu identity.
if df_porovnanie.loc[i, "Predpoved"] > prahova_hodnota:
df_porovnanie.loc[i, "Predpoved1"] = 1
else:
df_porovnanie.loc[i, "Predpoved1"] = 0
for i in range(len(df_porovnanie)):
if abs(df_porovnanie.loc[i, "Skutocnost"] - df_porovnanie.loc[i, "Predpoved1"]) <.01:
df_porovnanie.loc[i, "Vyhodnotenie"] = 'Správne'
else:
df_porovnanie.loc[i, "Vyhodnotenie"] = '-'
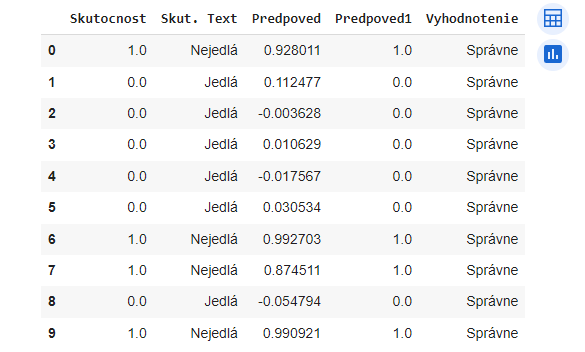
df_porovnanie.head(10)
Zistíme počet nesprávnych predpovedí
nespravne = 0
for i in range(len(df_porovnanie)):
if abs(df_porovnanie.loc[i, "Skutocnost"] - df_porovnanie.loc[i, "Predpoved1"]) >.01:
nespravne += 1
nespravne
---výpis---
9
V tomto prípade nie je však omyl ako omyl. Ak necháte jedlú hubu, ktorú algoritmus nesprávne určil ako jedovatú v lese, nestane sa nič. Opačný prípad, kedy algoritmus určí jedovatú hubu ako jedlú však môže mať tragické následky.
JedlaAkoNejedla = 0
NejedlaAkoJedla = 0
for i in range(len(df_porovnanie)):
#len pre nesprávne hodnoty
if abs(df_porovnanie.loc[i, "Skutocnost"] - df_porovnanie.loc[i, "Predpoved1"]) >.01:
if (df_porovnanie.loc[i, "Skutocnost"] >0.99):
NejedlaAkoJedla += 1
else:
JedlaAkoNejedla += 1
print("Nejedlá ako jedlá",NejedlaAkoJedla)
print("Jedlá ako nejedlá",JedlaAkoNejedla)
---výpis---
Nejedlá ako jedlá 9
Jedlá ako nejedlá 0
Kategorizácia húb je pomerne presná, aj napriek tomu, že sme do úvahy zobrali len 6 atribútov z 22.
Pre zaujímavosť dataminingový algoritmus SQL Servera 2012 z 4062 záznamov nesprávne určil len osem, čo je zanedbateľný zlomok percenta. Všetkých osem nesprávne určených prípadov bola nejedlá, prípadne jedovatá huba identifikovaná ako jedlá.