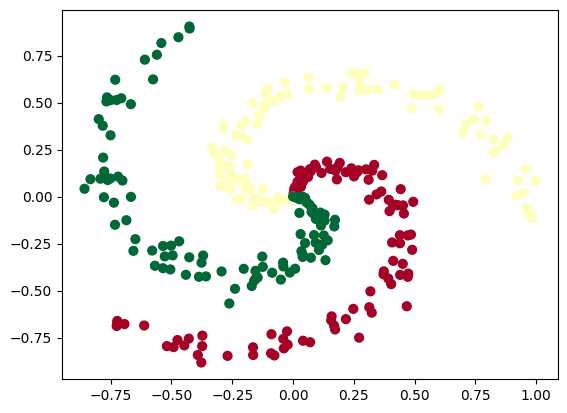
V prípade úloh tohoto typu nás zaujíma, čo to je, prípadne či nastane, alebo nenastane daná situácia.
Binárna klasifikácia - cieľ môže byť jednou z dvoch možností, napr. áno alebo nie. Napríklad či je huba jedlá, alebo nie je, či sledovaná osoba ochorie na danú chorobu, či bude schopná splácať úver a podobne. Zisťujeme to na základe zadaných parametrov.
Multi-class klasifikácia - cieľ identifikujeme výberom z viac ako dvoch možností. Napríklad o aký predmet, či zviera sa jedná, či je na obrázku pes, mačka, alebo morča a podobne.
Klasifikácia viacerých značiek (multi-label ) - cieľu možno priradiť viac ako jednu možnosť. Napríklad článok, či video môžeme zaradiť do viacerých kategórií. Typickým príkladom je jedlo a cestovanie
Video s príkladmi
Príklad binárnej klasifikácie
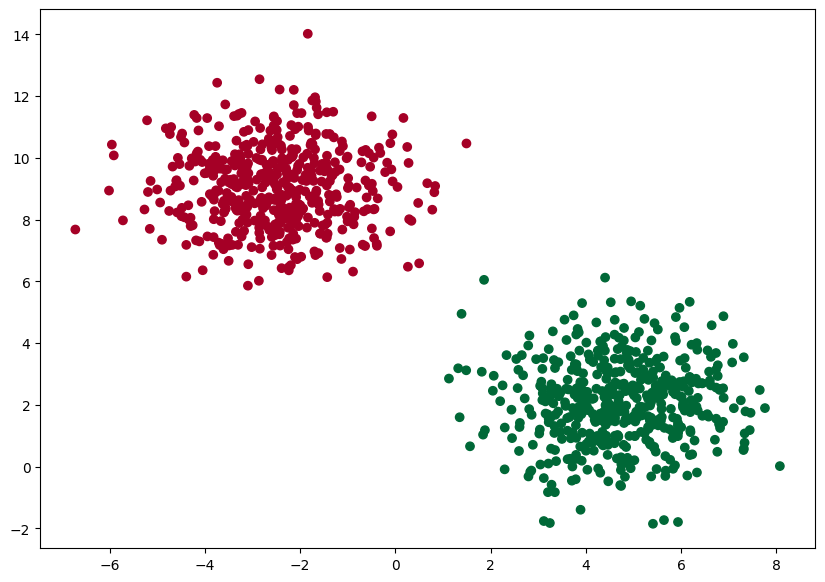
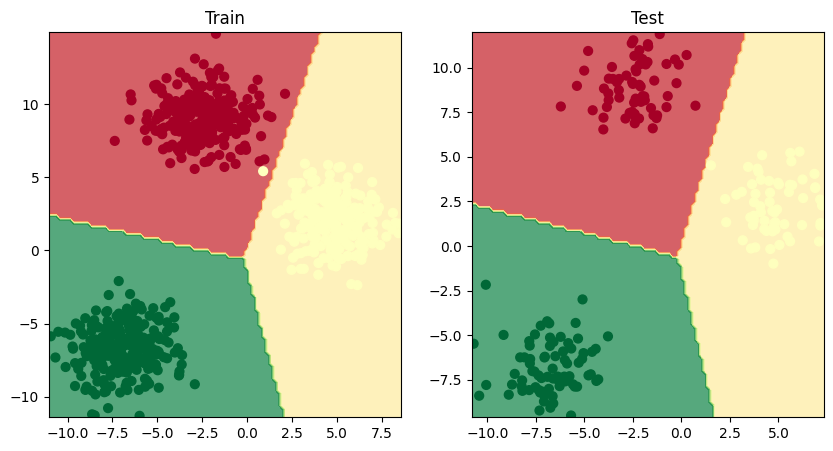
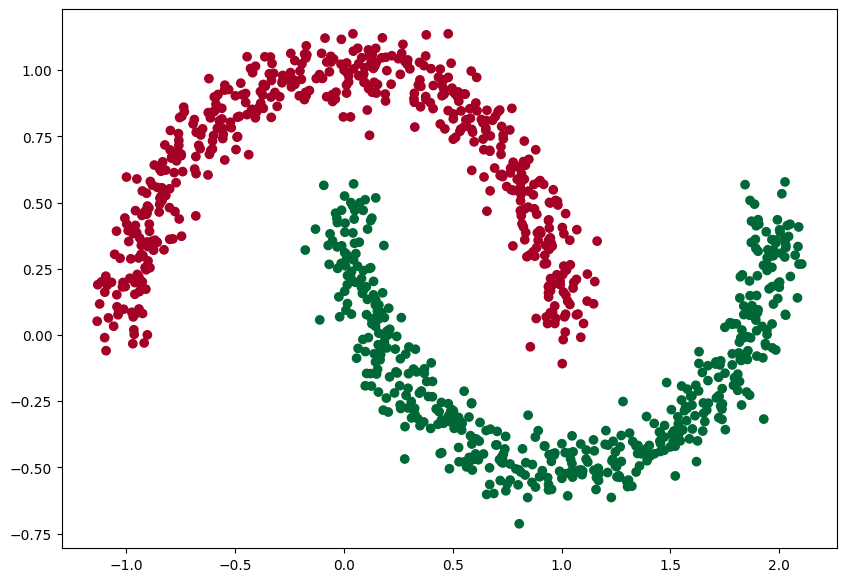
Na vygenerovanie vzoriek využijeme knižnicu Scikit Learn, konkrétne funkciu make_blobs() na generovanie zhlukov bodov
Údaje sú v poliach NumPy, pre výpočty s využitím knižnice PyTorch ich konvertujeme na tenzory.
X = torch.from_numpy(X).type(torch.float)
y = torch.from_numpy(y).type(torch.float)
# výpis prvých piatich hodnôt
X[:5], y[:5]
---výpis---
(tensor([[-1.4228, 7.5457],
[ 6.8209, 1.2535],
[ 3.2147, 0.1011],
[ 5.3196, 1.2274],
[ 4.4053, 6.1242]]),
tensor([0., 1., 1., 1., 1.]))
Rozdelíme údaje na trénovaciu a testovaciu množinu a na trénovacej množine natrénujeme model neurónovej siete, aby sa naučila rozpoznávať vzory. V trénovacej množine bude 80% údajov v testovacej 20 %
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
len(X_train), len(X_test), len(y_train), len(y_test) # kontrola veľkosti množín
---výpis---
(800, 200, 800, 200)
Vytvorenie modelu neurónovej siete
Využijeme triedu nn.Module. Na výpočet uprednostníme GPU ak máme k dispozícii kartu NVIDIA, takúto relatívne jednoduchú úlohu však v pohode zvládne aj CPU
Úlohou modelu je na základe vstupov X predpovedať výstupy y. Nakoľko model sa učí na známych prípadoch jedná sa o supervised learning.
V konštruktore vytvoríme dve nn.Linear vrstvy. Prvá vrstva self.layer_1 má 2 vstupné funkcie a vytvára 5 výstupných funkcií. Budeme teda využívať 5 skrytých neurónov. To umožní modelu učiť sa vzory z piatich čísel namiesto iba dvoch čísel, čo môže viesť k lepším výstupom. Zdôrazňujeme, že to môže a nemusí fungovať. Preto počet skrytých neurónov nastavíme ako parameter. Platí, že ďalšia vrstva, v našom prípade self.layer_2, musí mať rovnaké in_features ako predchádzajúca vrstva out_features.
Definujeme stratovú funkciu a optimizér Keďže pracujeme s problémom binárnej klasifikácie, použime funkciu binary cross entropy los, čiže funkciu straty binárnej krížovej entropie. Funkcia zisťuje, ako nesprávne sú predpovede modelu, čím vyššia je strata, tým horší je model.
PyTorch má dve implementácie binárnej krížovej entropie:
torch.nn.BCELoss() - vytvára stratovú funkciu, ktorá meria binárnu krížovú entropiu medzi cieľom a vstupom
torch.nn.BCEWithLogitsLoss() funguje rovnako avšak má zabudovanú sigmoidnú vrstvu (nn.Sigmoid), takže by mala byť stabilnejšia
Pre optimalizátor použijeme torch.optim.SGD() na optimalizáciu parametrov modelu s rýchlosťou učenia 0,1.
loss_fn = nn.BCEWithLogitsLoss() # so sigmoidnnou vrstvou
Logity sú nenormalizované predpovede modelu. Sú výstupom metódy forward(). Kým model nebol trénovaný, tieto výstupy sú v podstate náhodné. V štatistike je funkcia logit kvantilovou funkciou spojenou so štandardnou logistickou distribúciou. Má mnoho použití pri analýze údajov a strojovom učení, najmä pri transformáciách údajov. Aby sme dostali nespracované výstupy (logity) modelu do podoby v ktorej ich môžeme porovnávať s výsledkami použijeme aktivačnú funkciu sigmoid.
Reálne výstupy majú hodnotu 0, alebo 1, výstupy netrénovaného modelu sa pohybujú okolo 0,5. Čím bližšie je hodnota k 0, tým viac si model myslí, že vzorka patrí do triedy 0, čím bližšie k 1, tým viac si model myslí, že vzorka patrí do triedy 1
y_logits = model_1(X_test)[:5]
print (y_logits)
y_predpoved = torch.sigmoid(y_logits)
print(y_predpoved)
---výpis---
tensor([[0.2127],
[0.1823],
[0.1463],
[0.1845],
[0.2230]], grad_fn=)
tensor([[0.5530],
[0.5455],
[0.5365],
[0.5460],
[0.5555]], grad_fn=)
Trénovanie modelu
Slučka obsahuje tieto kroky:
Dopredný prechod - model prejde všetkými trénovacími údajmi a vykoná výpočty funkcie forward().
Výpočet straty - výstupy modelu, čiže predpovede sa porovnajú s výsledkami aby sa zistilo ako sa predpovede líšia od pravdy a vyhodnotia sa, aby sa zistilo, nakoľko sú nesprávne.
Nulové gradienty - gradienty optimalizátorov sú nastavené na nulu, takže je možné ich prepočítať pre konkrétny tréningový krok.
Backpropagation čiže spätné šírenie pri strate, Vypočíta sa gradient straty vzhľadom na každý parameter modelu, ktorý sa má aktualizovať
Aktualizácia optimalizátora (gradient descent čiže klesanie gradientu) Aktualizujú sa parametre s ohľadom na gradienty strát, aby sa zlepšili.
torch.manual_seed(42)
epochs = 100 # počet iterácií - koľkokrát model prechádza tréningové dáta
print(f"Iterácia: {epoch} - Loss: {loss:.5f}, Test loss: {test_loss:.5f}")
---výpis---
Iterácia: 0 - Loss: 0.71093, Test loss: 0.24971
Iterácia: 10 - Loss: 0.04977, Test loss: 0.03926
Iterácia: 20 - Loss: 0.02748, Test loss: 0.02068
...
Iterácia: 80 - Loss: 0.00901, Test loss: 0.00503
Iterácia: 90 - Loss: 0.00826, Test loss: 0.00444
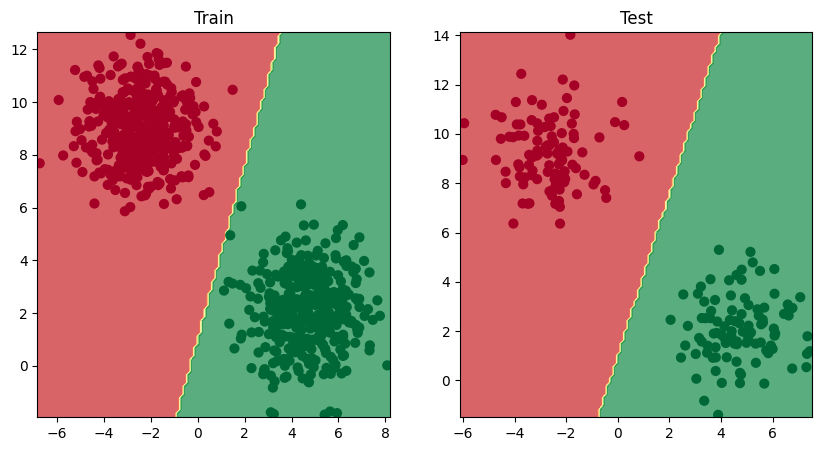
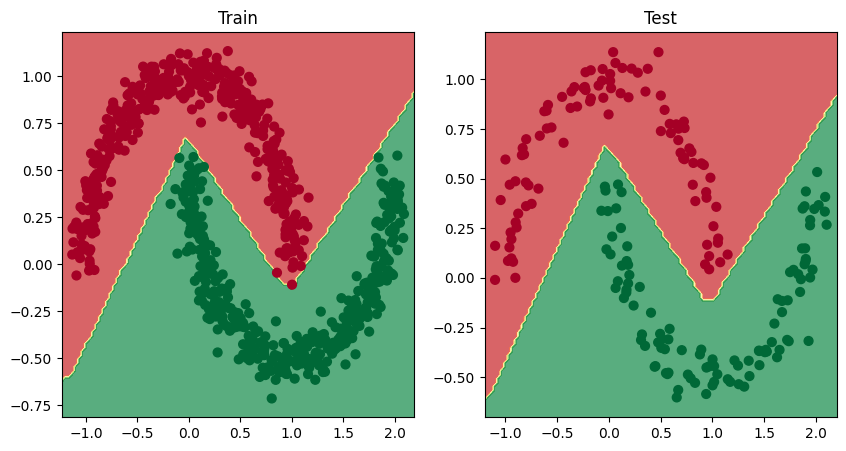
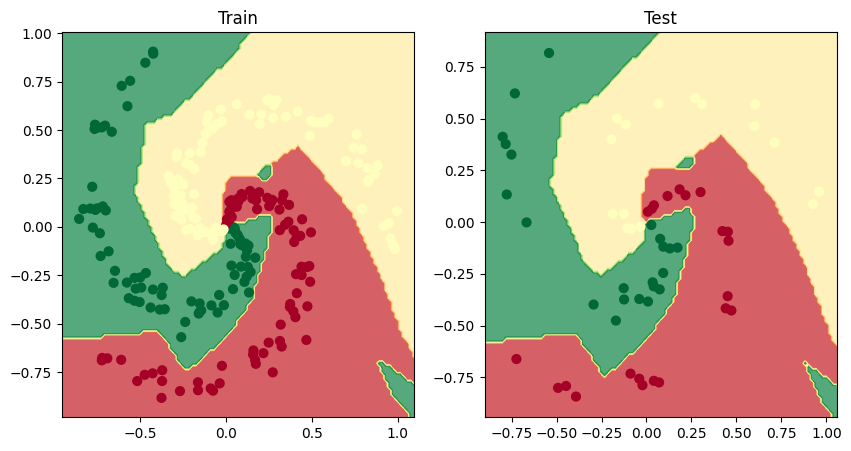
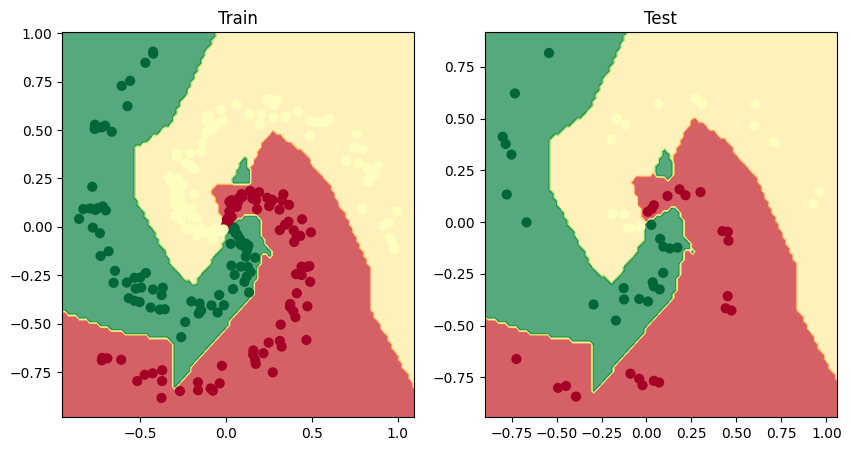
Oveľa názornejšie to bude, keď vizualizujeme hranice rozhodovania. Vytvoríme na tento účel funkciu, ktorá bude univerzálna pre binárnu aj multiclass kategorizáciu
Funkcia softmax vypočíta pravdepodobnosť, že každá predikčná trieda je skutočne predpovedanou triedou v porovnaní so všetkými ostatnými možnými triedami.
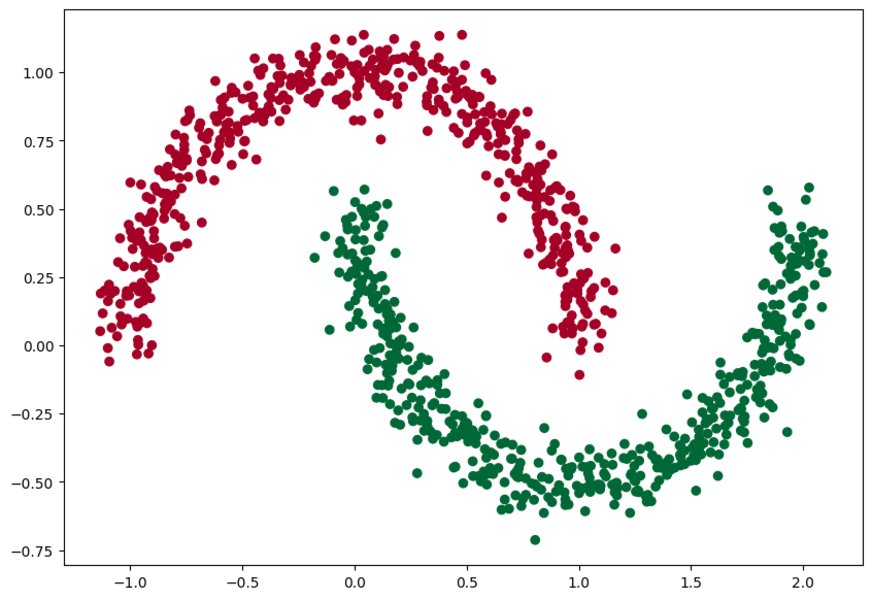
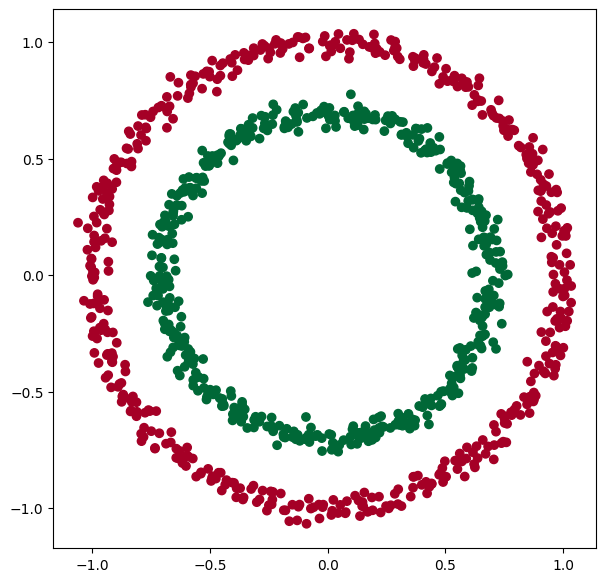
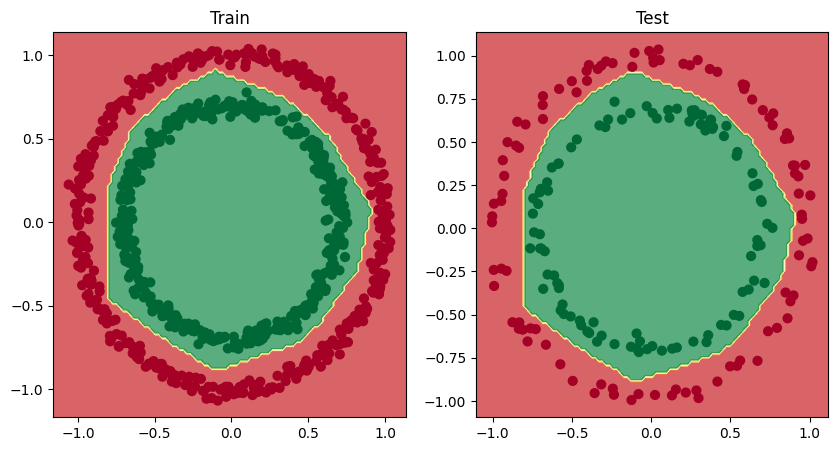
Dosiaľ tvorili hranice medzi zhlukmi objektov priamky. Ukážeme príklad, keď to bude krivka. Na vygenerovanie vzoriek využijeme knižnicu Scikit Learn, konkrétne funkciu na generovanie datasetov make_circles
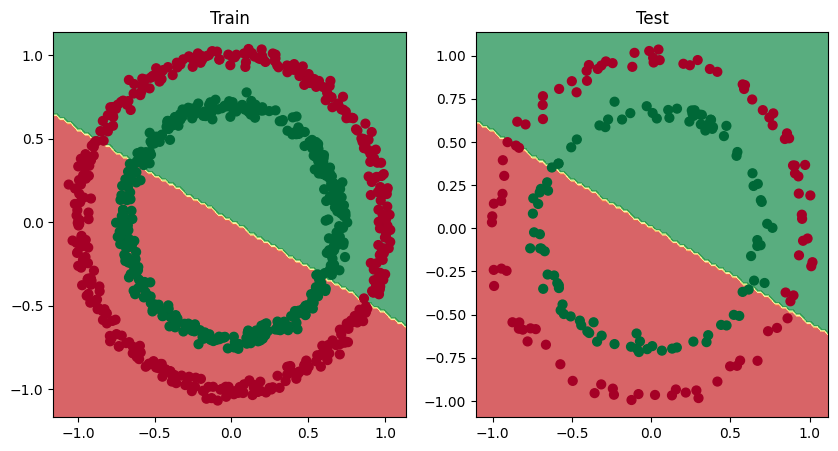
Model NS v aktuálnej podobe sa pokúša rozdeliť červené a zelené bodky pomocou hranice v tvare priamky. To vysvetľuje 50% presnosť. Kbody sú ale rozmiestnené v kruhoch. Model v tejto podobe nevyhovuje.
Vylepšenie modelu
Čo môžeme urobiť?
Pridanie ďalších vrstiev alebo prehĺbenie NS - každá vrstva potenciálne zlepšuje schopnosti učenia modelu, vie sa naučiť nový vzor v údajoch.
Pridanie skrytých neurónov alebo rozšírenie siete - viac skrytých jednotiek na vrstvu znamená potenciálne zlepšenie učebných schopností modelu
Dlhší tréning - počas väčšieho počtu iterácií by sa model mohol viac dozvedieť
Zmena aktivačnej funkcie - na niektoré prípady sa viac hodí snelineárna aktivačná funkcia
Zmena rýchlosti učenia - rýchlosť učenia optimalizátora, udáva ako model v každom kroku zmení parametre
Zmena stratovej funkcie - rôzne problémy vyžadujú rôzne stratové funkcie.
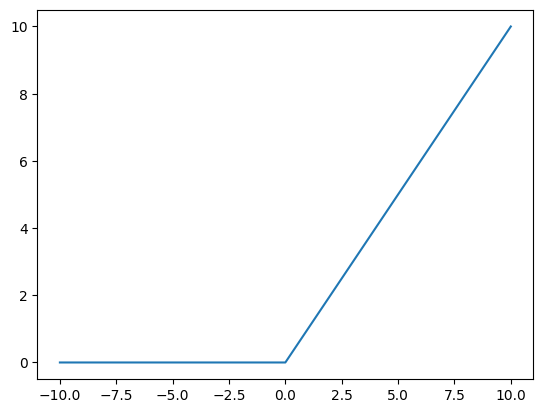
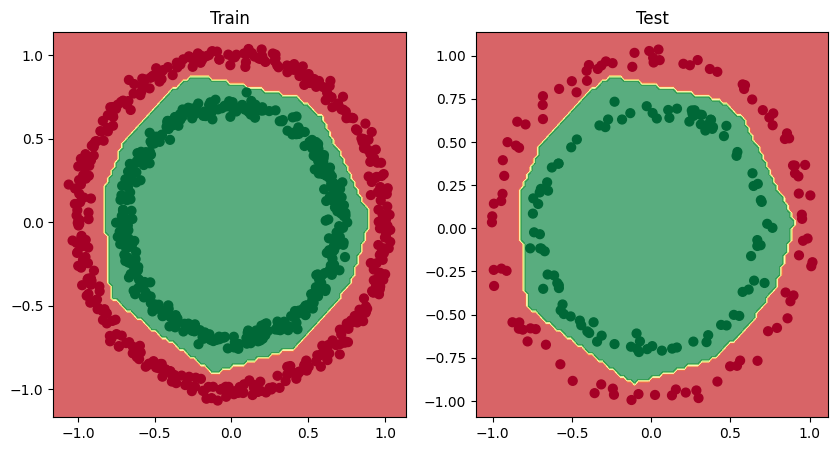
Pomôže model ktorý bude akceptovať nelineárny priebeh údajov, v našom prípade sú usporiadané do kruhov. Použijeme nelineárnu aktivačnú funkciu ReLu.